EMC just announced the general availability of VSPEX Blue. VSPEX Blue is basically EMC’s version of EVO:RAIL and EMC wouldn’t be EMC if they didn’t do something special with it. First thing that stands out from a hardware perspective is that EMC will offer two models a standard model with the Intel E5-2620 V2 proc and 128GB of memory, and a performance model which will hold 192GB of memory. That is the first time I have seen an EVO:RAIL offering with different specs. But that by itself isn’t too exciting…
EMC just announced the general availability of VSPEX Blue. VSPEX Blue is basically EMC’s version of EVO:RAIL and EMC wouldn’t be EMC if they didn’t do something special with it. First thing that stands out from a hardware perspective is that EMC will offer two models a standard model with the Intel E5-2620 V2 proc and 128GB of memory, and a performance model which will hold 192GB of memory. That is the first time I have seen an EVO:RAIL offering with different specs. But that by itself isn’t too exciting…
When reading the spec sheet the following bit stood out to me:
EMC VSPEX BLUE data protection incorporates EMC RecoverPoint for VMs and VMware vSphere Data Protection Advanced. EMC RecoverPoint for VMs offers operational and disaster recovery, replication and continuous data protection at the VM level. VMware vSphere Data Protection Advanced provides centralized backup and recovery and is based on EMC Avamar technology. Further, with the EMC CloudArray gateway, you can securely expand storage capacity without limits. EMC CloudArray works seamlessly with your existing infrastructure to efficiently access all the on-demand public cloud storage and backup resources you desire. EMC VSPEX BLUE is backed by a single point of support from EMC 24×7 for both hardware and software.
EMC is including various additional pieces of software including vSphere Data Protection Advanced for backup and recovery, EMC Recovery Point for disaster recovery, EMC CloudArray gateway and the EMC VSPEX BLUE management software and EMC Secure Remote Service which will allow for monitoring, diagnostics and repair services. This of course will differ per support offering, and there are currently 3 support offerings (basic, enhanced, premium). Premium is where you get all the bells and whistles with full 24x7x4 support.
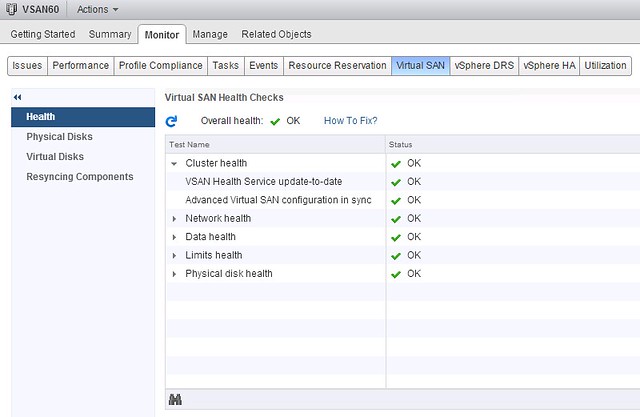
What is special about the management / support software in this case is that EMC took a different approach then normal. In this case the VSPEX BLUE interface will allow you to directly chat with support folks, dig up knowledge base articles and even the community is accessible from within. Also, the management layer will monitor the system and if something fails then EMC will contact you, also known as “phone home”. Besides the fact that the UI is a couple of steps ahead of anything I have seen so far, it looks like EMC will directly tie in with LogInsight which will provide deep insights from the hardware to the software stack. What also impressed me were the demos they provided and how they managed to create the same look and feel as the EVO:RAIL interface.
EMC also mentioned that they are working on a market place. This market place will allow you to deploy certain additional services, in this example you can see CloudArray, RecoverPoint and VDPA but more should be added soon! Will be interesting to see what kind of services will end up in the market place. I do feel that this is a great way of adding value on top of EVO:RAIL.
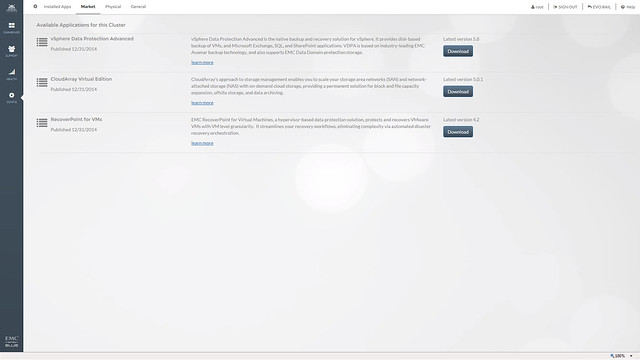
One of the services in the market place that stood out to me was CloudArray. So what about that EMC CloudArray gateway solution, what can you do with that? The CloudArray solution allows you to connect external offsite store as iSCSI or NFS to the appliance. It can be used for everything, but what I find most compelling is that it will allow you to replicate your backup data off-site. The CloudArray will come with 1TB local cache and 10 TB cloud storage!
I have to say that EMC did a great job packing the EVO:RAIL offering with additional pieces of software and I believe they are going to do well with VSPEX BLUE, in fact I would not be surprised if they are going to be the number 1 qualified partner in terms of sales really fast. If you are interested, the offering will be shipping on the 16th of February, but can be ordered today!
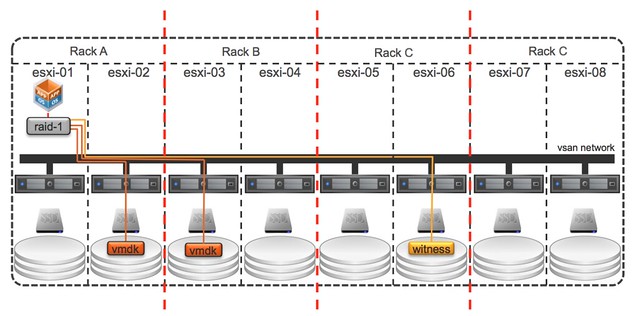
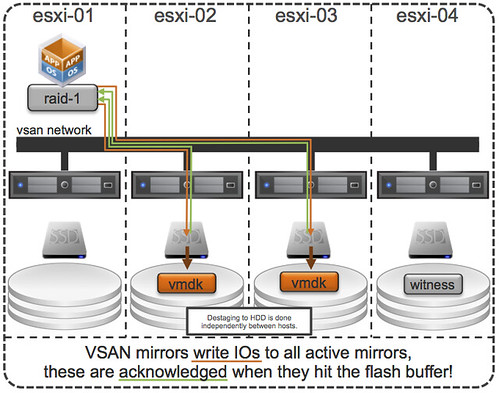
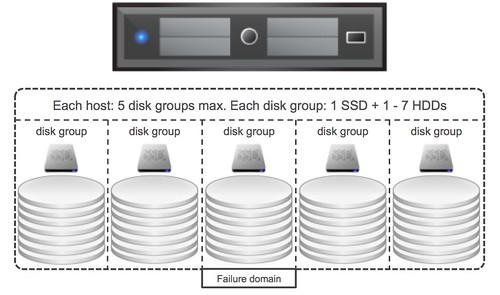
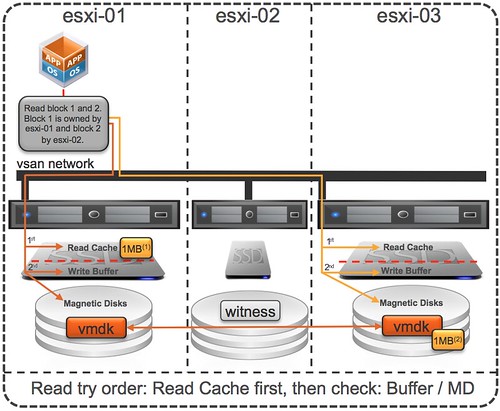
 That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.
That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.