Every now and then customers ask if it is possible to check if disk controllers are on the VSAN HCL (Or VMware Compatibility Guide (VCG) as it is actually called these days) for a given set of hosts through PowerCLI. Alan Renouf figured he would knock something out, thanks Alan for sharing! (Next up would be validate drivers and firmware of all components, thanks!) What this script does is the following, note that you need internet access for this to work:
- Connect to vCenter
- Download latest VSAN HCL details (json file)
- Compare controllers of each host against the VSAN HCL
- Report the state of your infra
Here is the script, it can also be found in the VMware Developer Center repository by the way.
Connect-VIServer myvcenter -user Administrator -password MyPass23
Function Get-CompatibleVSANController {
if (-Not $vSANHCL) {
$vSANHCL = Invoke-WebRequest -Uri http://partnerweb.vmware.com/service/vsan/all.json | ConvertFrom-Json
}
$vSANHCL.data.controller
}
$HBAs = get-vmhost | Get-VMHostPciDevice | where { $_.DeviceClass -eq "MassStorageController" }
Foreach ($HBA in $HBAs) {
$HBAFound = $false
Write-Host "Looking for $($hba.name) from host $($HBA.VMhost)"
Foreach ($entry in Get-CompatibleVSANController) {
$vid = [String]::Format("{0:x}", $HBA.VendorId)
$did = [String]::Format("{0:x}", $HBA.DeviceId)
$svid = [String]::Format("{0:x}", $HBA.SubVendorId)
$ssid = [String]::Format("{0:x}", $HBA.SubDeviceId)
If (($vid -eq $entry.vid) -and ($did -eq $entry.did) -and ($svid -eq $entry.svid) -and ($ssid -eq $entry.ssid) ) {
Write-Host " HBA in $($HBA.VMHost) is $($HBA.Name) which can be found in the HCL as $($Entry.vendor) - $($Entry.Model) at the following URL: `n $($entry.vcglink)" -ForegroundColor Green
$HBAFound = $true
}
}
If (-Not $HBAFound){
Write-Host " $($HBA.Name) in $($HBA.VMHost) is not found!" -ForegroundColor Red
}
}
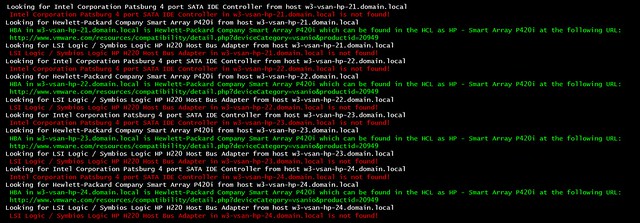
If you run it the output will look like this: