Over the last couple of weeks I have been talking to customers a lot about VSAN 6.2 and how to design / size their environment correctly. Since the birth of VSAN we have always spoken about 10% cache to capacity ratio to ensure performance is where it needs to be. When I say 10% cache to capacity ratio, I should actually say the following:
The general recommendation for sizing flash capacity for Virtual SAN is to use 10% of the anticipated consumed storage capacity before the NumberOfFailuresToTolerate is considered.
Reality is though that what most customers did was they looked at their total capacity, cut it in half (FTT=1) and then said “we will take 10%” of that. So a 10TB VSAN Datastore would require “10% of 5TB” in terms of cache. This is fast way of indeed calculating what your caching requirements are… That is, if ALL of your virtual machines have the same “availability” requirements. Because even in 6.1 and prior the outcome would change if you had VMs which required FTT=2 or FTT=3 or even FTT=0. (Although I would not recommend FTT=0.)
With VSAN 6.2 this is amplified even more. Why? Well as you hopefully read, VSAN 6.2 introduces space efficiency functionality (for all-flash) like deduplication, compression, RAID-5 or RAID-6 over the network. The following diagram depicts what that looks like. In this case we show RAID-6 with 4 data blocks and 2 parity blocks, which is capable of tolerating 2 failures anywhere in the cluster of 6 hosts.
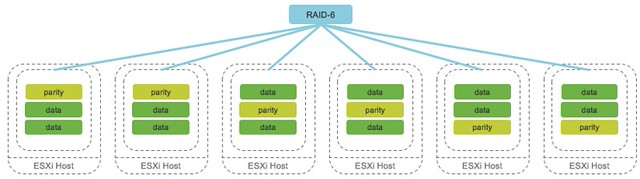
If you look at the above, and take that old “FTT=1” or “FTT=2” diagram in mind you quickly realize that the effective capacity per datastore is not as easy to calculate as it was in the past. Lets take a look at a simple example to show the impact which using certain data services can have on your design / sizing.
- 1000 VMs with on average 50GB disk space required
- 1000 * 50GB = 50TB
Lets take a look at both FTT=1 and FTT=2 with and without Raid-5/6 enabled. The calculations are pretty simple. Note that “FTT” stands for “Failures to Tolerate” and FTM stands for “Failure Tolerance Method”.
| FTT | FTM | Calculation | Result |
|---|---|---|---|
| 1 | Raid-1 | 1000 VMs * 50GB * 2 (overhead) | 100TB |
| 1 | Raid-5/6 | 1000 VMs * 50GB * 1.33 (overhead) | 66.5TB |
| 2 | Raid-1 | 1000 VMs * 50GB * 3 (overhead) | 150TB |
| 2 | Raid-5/6 | 1000 VMs * 50GB * 1.5 (overhead) | 75TB |
Now if you look at the table, you will see there is a big difference between the capacity requirements for FTT=2 using RAID-1 and FTT=2 using RAID-5/6 even between the FTT=1 variations the difference is significant. You can imagine that when you base your required cache capacity simply on the required disk capacity that the math will be off. Assuming that the amount of hot data in all cases is 10% the difference could be substantial. However, when you base your cache requirements on the initial 10% of “1000* 50GB” the result never changes!
And in this case I haven’t even taken deduplication and compression in to account, you can imagine that with a data reduction of 2x using VSAN compression and deduplication that the math will change again for the caching tier, well that is if you do it wrong and calculate it based on the actual capacity layer… To summarize, when you do your VSAN design and sizing, make sure to always base it on the Virtual Machine size, it is the safest and definitely the easiest way to do the math!
For more details on RAID-5/6 and – or on Deduplication and Compression make sure to read Cormac’s excellent articles on these topics.
Duncan, is it possible to migrate from VSAN 6.1 with Raid-1 configuration to VSAN 6.2 with Raid-5/6 “on the fly”?
Second, it’s possible in 6.2 get Hybrid (raid-1) and pure Flash (raid-5/6) configuration on same Vsan cluster?
You can only have 1 type of disk group in a cluster with this version. it is a request we get more often and I will inform the PM team about your request. When it comes to upgrades from R1 to R5, yes this can be done on the fly in an all-flash cluster. Simply change the policy of the VM and you are done!
The RAID policy that you talk of is configured at the virtual machine level through the use of storage policies, and not the VSAN Datastore – you can change your storage policies on the fly. Obviously erasure coding is only available on all-flash though.
I don’t believe that you can have hybrid and all-flash in the same cluster.
Good morning Duncan, it seems like you’re saying that even less cache may be needed if you consider dedupe and compression. My impression is that that happens between the cache and capacity as it destages. Wouldn’t you still need the same amount of cache with dedupe and compression because that’s where it lands first? Thank you, Zach.
note that dedupe and compression happens before the destaging but after it has reached the caching tier. you still need the 10% cache ratio from a VM point of view, regardless of whether it is more or less at the back-end. Reason for this is that as stated the “hot data” doesn’t change and will need to reside within the “write buffer”. I hope that clears things up Zach.
Hi Duncan,
In the design and sizing guide, the calculation of the cache layer is done on the Raw storage, so after taking into account dedup/compression. Which would make it much less than what would actually hit the cache If dedupe kicks in afterwards.
Could you check it out and explain wether I missunderstood the use case or if something is wrong/changed in the guide. Page 101 (option 3), use case detailed page 95 (Example II):
http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/products/vsan/virtual-san-6.2-design-and-sizing-guide.pdf
I am currently learning and sizing our potential next project with the VMware docs and use cases. The tco tool is good but I like to understand all the sizing.
Thanks!
the example is the same as I am doing, just explained in a different way. “raw storage” referring to VM raw storage requirements. Not “datastore raw storage requirements”.
Ok so when you say “you still need the 10% cache ratio from a VM point of view”, you mean the size of the VM from a guest OS point of view ? (which isn’t aware of the dedupe/compression/FTT mecanism).
Say, a VM with a 100GB VMDK with FTT=1 and dedup 2x will still need 10GB in the caching layer?
In the sizing guide it’s like:
100 GB * 1.33 (Raid5) / 4 (dedupe) * (Guest usage, say 100% for simplicity) <= the 10% cache is then based on that which would be 3.325GB.
I probably just missed something
Hi Duncan,
This makes explaining a design a lot easier. I do wonder if dividing the FTT=1 and FTT=2 into different disk groups would make sense to you? Since I’m planning FTT=2 (on RAID5) mainly for DBs it could benefit from the extra IOPS that come available when splitting into disk groups.
I couldn’t find if mixing all flash & hybrid disks in different disk groups is possible. Any ideas on that?
At this point in time you can only have a single type of diskgroup in a cluster… it is a common request though, so you can imagine that this may be something that will come at some point in time
HI Duncan
with respect to the size of virtual machines should take into account the size of the vmdk in thick or thin provisioning?