Yesterday the paper that Chris Colotti and I were working on titled “VMware vCloud Director Infrastructure Resiliency Case Study” was finally published. This white paper is an expansion on the blog post I published a couple of weeks back.
Someone asked me at PEX where this solution came from all of a sudden, well this is based on a solution I came up with on a random Friday morning half of December when I woke up at 05:00 in Palo Alto still jet-lagged. I diagrammed it on a napkin and started scribbling things down in Evernote. I explained the concept to Chris over breakfast and that is how it started. Over the last two months Chris (+ his team) and I validated the solution and this is the outcome. I want to thank Chris and team for their hard work and dedication.
I hope that those architecting / implementing DR solutions for vCloud environments will benefit from this white paper. If there are any questions feel free to leave a comment.
Source – VMware vCloud Director Infrastructure Resiliency Case Study
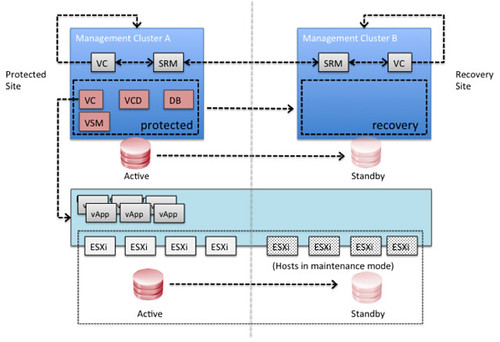
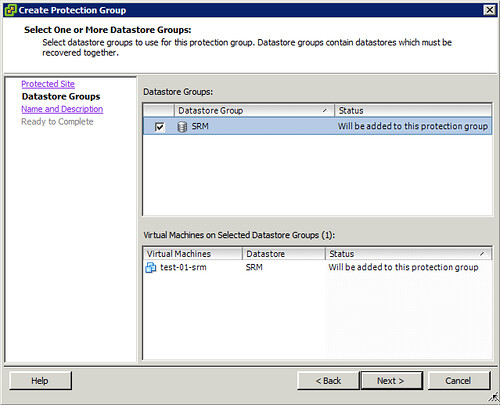
Description: vCloud Director disaster recovery can be achieved through various scenarios and configurations. This case study focuses on a single scenario as a simple explanation of the concept, which can then easily be adapted and applied to other scenarios. In this case study it is shown how vSphere 5.0, vCloud Director 1.5 and Site Recovery Manager 5.0 can be implemented to enable recoverability after a disaster.
Download:
http://www.vmware.com/files/pdf/techpaper/vcloud-director-infrastructure-resiliency.pdf
http://www.vmware.com/files/pdf/techpaper/vcloud-director-infrastructure-resiliency.epub http://www.vmware.com/files/pdf/techpaper/vcloud-director-infrastructure-resiliency.mobi
I am expecting that the MOBI and EPUB version will also soon be available. When they are I will let you know!