By Chris Colotti (Consulting Architect, Center Of Excellence) and Duncan Epping (Principal Architect, Technical Marketing)
This article assumes the reader has knowledge of vCloud Director, Site Recovery Manager and vSphere. It will not go in to depth on some topics, we would like to refer to the Site Recovery Manager, vCloud Director and vSphere documentation for more in-depth details around some of the concepts.
Creating DR solutions for vCloud Director poses multiple challenges. These challenges all have a common theme. That is the automatic creation of objects by VMware vCloud Director such as resource pools, virtual machines, folders, and portgroups. vCloud Director and vCenter Server both heavily rely on management object reference identifiers (MoRef ID’s) for these objects. Any unplanned changes to these identifiers could, and often will, result in loss of functionality as Chris has described in this article. vSphere Site Recovery Manager currently does not support protection of virtual machines managed by vCloud Director for these exact reasons.
The vCloud Director and vCenter objects, which are referenced by each product, that are both identified to cause problems when identifiers are changed are:
- Folders
- Virtual machines
- Resource Pools
- Portgroups
Besides automatically created objects the following pre-created static objects are also often used and referenced to by vCloud Director.
- Clusters
- Datastores
Over the last few months we have worked on, and validated a solution which avoids changes to any of these objects. This solution simplifies the recovery of a vCloud Infrastructure and increases management infrastructure resiliency. The amazing thing is it can be implemented today with current products.
In this blog post we will give an overview of the developed solution and the basic concepts. For more details, implementation guidance or info about possible automation points we recommend contacting your VMware representative and you engage VMware Professional Services.
Logical Architecture Overview
vCloud Director infrastructure resiliency can be achieved through various scenarios and configurations. This blog post is focused on a single scenario to allow for a simple explanation of the concept. A white paper explaining some of the basic concepts is also currently being developed and will be released soon. The concept can easily be adapted for other scenarios, however you should inquire first to ensure supportability. This scenario uses a so-called “Active / Standby” approach where hosts in the recovery site are not in use for regular workloads.
In order to ensure all management components are restarted in the correct order, and in the least amount of time vSphere Site Recovery Manager will be used to orchestrate the fail-over. As of writing, vSphere Site Recovery Manager does not support the protection of VMware vCloud Director workloads. Due to this limitation these will be failed-over through several manual steps. All of these steps can be automated using tools like vSphere PowerCLI or vCenter Orchestrator.
The following diagram depicts a logical overview of the management clusters for both the protected and the recovery site.

In this scenario Site Recover Manager will be leveraged to fail-over all vCloud Director management components. In each of the sites it is required to have a management vCenter Server and an SRM Server which aligns with standard SRM design concepts.
Since SRM cannot be used for vCloud Director workloads there is no requirement to have an SRM environment connecting to the vCloud resource cluster’s vCenter Server. In order to facilitate a fail-over of the VMware vCloud Director workloads a standard disaster recovery concept is used. This concept leverages common replication technology and vSphere features to allow for a fail-over. This will be described below.
The below diagram depicts the VMware vCloud Director infrastructure architecture used for this case study.
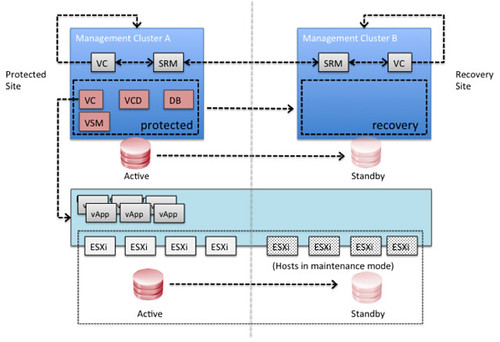
Both the Protected and the Recovery Sites have a management cluster. Each of these contain a vCenter Server and an SRM Server. These are used facilitate the disaster recovery procedures. The vCloud Director Management virtual machines are protected by SRM. Within SRM a protection group and recovery plan will be created to allow for a fail-over to the Recovery Site.
Please note that storage is not stretched in this environment and that hosts in the Recovery Site are unable to see storage in the Protected Site and as such are unable to run vCloud Director workloads in a normal situation. It is also important to note that the hosts are also attached to the cluster’s DVSwitch to allow for quick access to the vCloud configured port groups and are pre-prepared by vCloud Director.
These hosts are depicted as hosts, which are placed in maintenance mode. These hosts can also be stand-alone hosts and added to the vCloud Director resource cluster during the fail-over. For simplification and visualization purposes this scenario describes the situation where the hosts are part of the cluster and placed in maintenance mode.
Storage replication technology is used to replicate LUNs from the Protected Site to the Recover Site. This can be done using asynchronous or synchronous replication; typically this depends on the Recovery Point Objective (RPO) determined in the service level agreement (SLA) as well as the distance between the two sites. In our scenario synchronous replication was used.
Fail-over Procedure
In this section the basic steps required for a successful fail-over of a VMware vCloud Director environment are described. These steps are pertinent to the described scenario.
It is essential that each component of the vCloud Director management stack be booted in the correct order. The order in which the components should be restarted is configured in an SRM recovery plan and can be initiated by SRM with a single button. The following order was used to power-on the vCloud Director management virtual machines:
- Database Server (providing vCloud Director, vCenter Server, vCenter Orchestrator, and Chargeback Databases)
- vCenter Server
- vShield Manager
- vCenter Chargeback (if in use)
- vCenter Orchestrator (if in use)
- vCloud Director Cell 1
- vCloud Director Cell 2
When the fail-over of the vCloud Director management virtual machines in the management cluster has succeeded, multiple steps are required to recover the vCloud Director workload. These are described in a manual fashion but can be automated using PowerCLI or vSphere Orchestrator.
- Validate all vCloud Director management virtual machines are powered on
- Using your storage management utility break replication for the datastores connected to the vCloud Director resource cluster and make the datastores read/write (if required by storage platform)
- Mask the datastores to the recovery site (if required by storage platform)
- Using ESXi command line tools mount the volumes of the vCloud Director resource cluster on each host of the cluster
- esxcfg-volume –m <volume ID>
- Using vCenter Server rescan the storage and validated all volumes are available
- Take the hosts out of maintenance mode for the vCloud Director resource cluster (or add the hosts to your cluster, depending on the chosen strategy)
- In our tests the virtual were automatically powered on by vSphere HA. vSphere HA is aware of the situation before the fail-over and will power-on the virtual machines according to the last known state
- Alternatively, virtual machines can be powered-on manually leveraging the vCloud API to they are booted in the correct order as defined in their vApp metadata. It should be noted that this could possibly result in vApps being powered-on which were powered-off before the fail-over as there is currently no way of determining their state.
Using this vCloud Director infrastructure resiliency concept, a fail-over of a vCloud Director environment has been successfully completed and the “cloud” moved from one site to another.
As all vCloud Director management components are virtualized, the virtual machines are moved over to the Recovery Site while maintaining all current managed object reference identifiers (MoRef IDs). Re-signaturing the datastore (giving it a new unique ID) has also been avoided to ensure the relationship between the virtual machines / vApps within vCloud Director and the datastore remained in tact.
Is that cool and simple or what? For those wondering, although we have not specifically validated it, yes this solution/concept would also apply to VMware View. Yes it would also work with NFS if you follow my guidance in this article about using a CNAME to mount the NFS datastore.
This is great guys! I will definitely be trying this out in my lab in the next few days.
Isn’t it amazing what you can do when you have a fully virtualized environment like this?
Keep up the great posts!
Thanks Tim. indeed amazing how much you can do when you abstract all layers!
A great way to provide a resilient cloud. This could very well develop into a product for Cloud Recovery if we standardize it around certain specific use cases. Will wait for the whitepaper mentioned in the blog. Thanks Duncan for the insight.
cheers
Sunny
This is great stuff Duncan, your article was mentioned in a WebEx yesterday in the stretched cluster context and has subsequently resulted in some ongoing discussion around potential alternatives for protecting the vCloud resource cluster VMs. It’s one of the reasons I got into this game, love discussing and solving problems that have that added hint of complexity 🙂