Today PernixData presented at Virtualization Field Day 5. Excellent presentation by Satyam once again. This week I was fortunate to catch up with Frank Denneman to discuss what was going to be announced and what can be expected in the near future. I want to make it clear that there were no expectations given around release dates, don’t expect this to drop next week.
There were 4 key announcements:
- PernixData Architect – A better way to design, operate, and optimize data centers
- PernixData Cloud – Making enterprise IT more transparent
- PernixData FVP
- Freedom – Yes, “free” is the key word here!
- New features / functionality…
I am going to go at this in a different order than the deck, as I want to cover some of the changes with regards to FVP first. Satyam spoke about a new thing called “FVP Freedom“. FVP Freedom is a free version of FVP which can be used by anyone in any environment. Of course there are some constraints / limitations and these are:
- Up to 128GB DFTM cluster for write through acceleration
- Community support
However, you can use FVP Freedom for an unlimited number of hosts and unlimited number of VMs. Note that “DFTM” stands for Distributed Fault Tolerant Memory. This means that FVP Freedom gives you memory (read) caching only, no SSD caching. (128GB limit per cluster) I think this is huge, and it is a very smart way of getting people to test your solution and run it in production. So what can you do with 128GB? Well of course they tested this, and they were capable of increasing the VSImax users from 181 to 328 with that 128GB of memory on 2 hosts. You may wonder why they took this approach cause what does giving it away for free bring them? Well that will be obvious when you read the other announcements.
Besides a free version of FVP some enhancements to the current version were also announced. For me support for vSphere 6.0 and VVols were two major items. On top of that new “phone home” functionality is build in, which allows for better and pro-active support. What also stood out was the new stand alone UI. This means that you will be taken out of the Web Client to a standalone HTML5+JS based interface. You may wonder why they did this, that is where the two new product announcements come in to play. FVP is still a Windows installable by the way, I hoped they would announce an appliance which lowers complexity in terms of installation and management, but maybe next time who knows.
PernixData Architect was the first announcement. It is a piece of software that enables you to monitor your infrastructure (storage focussed of course) and make educated decisions based on the information and even recommendations provided. So what are we talking about in terms of metrics etc? PernixData Architect (for now?) is focussed on storage, not just from a cluster point of view, but also from a host level and virtual machine level. What is the latency a virtual machine is experiencing? How many IOPS does this VM do on average? What is the throughput? What is the read/write ratio? What are common block sizes? All the things you would like to know when designing, scaling, sizing your storage infrastructure and of course when using FVP.
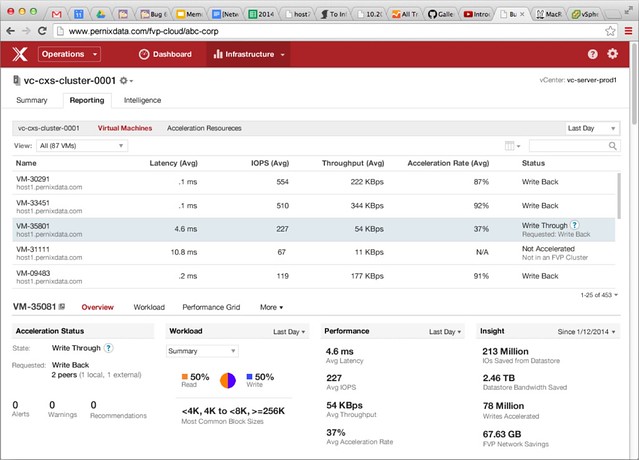
Besides the details above you can for instance also see what the active working set is in your environment for any of your VMs. You can even get recommendations around how to configure FVP, you may have it set to write back but if you are mainly serving reads from cache you may want to change that for instance. It will also give you other recommendations for instance around networking etc.
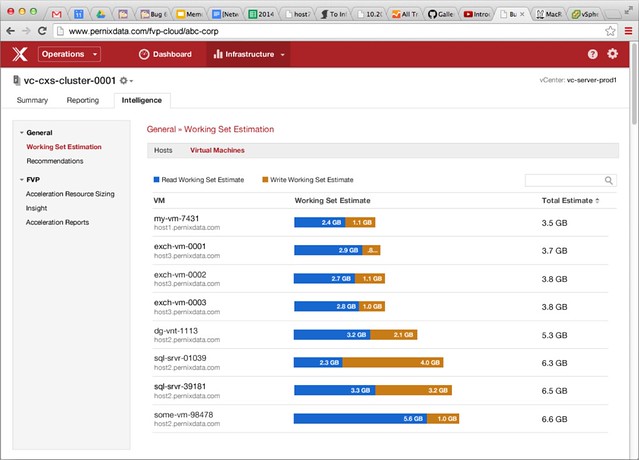
You can imagine that with all the metrics and info they are gathering they will be able to provide you much more recommendations in the future. I can see those dashboards expanding fast, and I think it is valuable for everyone to understand how their workloads are behaving. On twitter some comments were made about vR Ops and CloudPhysics. Not a fair comparison as Pernix is focussed on “just” storage for now. Personally I hope they will start tying in other aspects like memory, cpu and networking as I don’t think customers want to be stuck with 2 or 3 monitoring solutions.
Now that you have all that data, what can you do with it? Well that is where PernixData Cloud comes in. PernixData Cloud can give you Insights in to how you are doing compared to others in the industry with similar environments, or even with different environments. Those running PernixData Architect can feed it in to the cloud analytics platform and do an analysis on it. But what if they don’t? How useful is this cloud analytics platform going to be? Well here is the catch, when you use FVP Freedom one of the requirements will be to upload your statistics and environmental details in to PernixData Cloud. So, what kind of data can you get out of it? Let me give you two visual examples as that shows immediately why this is valuable:
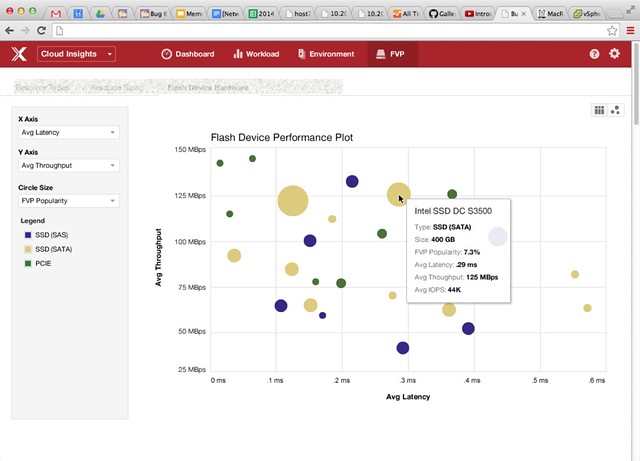
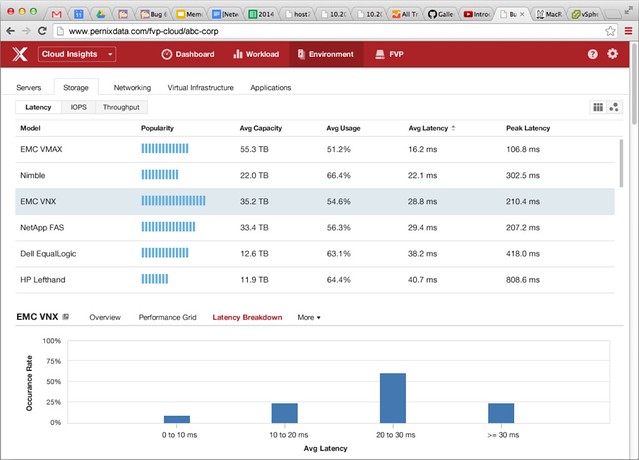
Both of the above examples demonstrate what PernixData Cloud Insights can give you. Data that is going help making purchasing decisions, and I can see how it could also be useful in the future for making design decisions. (Here is what others did to achieve X.) Best example is the top screenshot, not sure which flash device to buy? What are others buying? What can you expect out of it in terms of latency/throughput/IOPS? Cloud Insights will enable you to make educated decisions based on real life environments instead of based on fact-sheets which always appear to be misleading.
All in all, exciting news / announcements from PernixData at Virtualization Field Day 5. Nice work guys, and thanks Mr Denneman for taking the time to have a chat with me and thanks Mr Foskett for streaming the event live!