During Storage Field Day today PernixData announced a whole bunch of features that they are working on and will be released in the near future. In my opinion there were four major features announced:
- Support for NFS
- Network Compression
- Distributed Fault Tolerant Memory
- Topology Awareness
Lets go over these one by one:
Support for NFS is something that I can be brief about I guess; as it is what it says it is. Something that has come up multiple times in conversations seen on twitter around Pernix and it looks like they have managed to solve the problem and will support NFS in the near future. One thing I want to point out, PernixData does not introduce a virtual appliance in order to support NFS or create an NFS server and proxy the IOs, sounds like magic right… Nice work guys!
It gets way more interesting with Network compression. What is it, what does it do? Network Compression is an adaptive mechanism that will look at the size of the IO and analyze if it makes sense to compress the data before replicating it to a remote host. As you can imagine especially with larger block sizes (64K and up) this could significantly reduce the data that is transferred over the network. When talking to PernixData one of the questions I had was well what about the performance and overhead… give me some details, this is what they came back with as an example:
- Write back with local copy only = 2700 IOps
- Write back + 1 replica = 1770 IOps
- Write back + 1 replica + network compression = 2700 IOps
As you can see the number of IOps went down when a remote replica was added. However, it went up again to “normal” values when network compression was enabled, of course this test was conducted using large blocksizes. When it came to CPU overhead it was mentioned that the overhead so far has been demonstrated to be negligible.You may ask yourself why, it is fairly simple: the cost of compression weighs up against the CPU overhead and results in an equal performance due to lower network transfer requirements. What also helps here is that it is an adaptive mechanism that does a cost/benefit analyses before compressing. So if you are doing 512 byte or 4KB IOs then network compression will not kick in, keeping the overhead low and the benefits high!
I personally got really excited about this feature: DFTM = Distributed Fault Tolerant Memory. Say what? Yes, distributed fault tolerant memory! FVP, indeed besides virtualizing flash, can now also virtualize memory and create an aggregated pool of resources out of it for caching purposes. Or in a more simplistic way: what they allow you to do is reserve a chunk of host memory as virtual machine cache. Once again happens on a hypervisor level, so no requirement to run a virtual appliance, just enable and go! I would want to point out though that there is “cache tiering” at the moment, but I guess Satyam can consider that as a feature request. Also, when you create an FVP cluster hosts within that cluster will either provide “flash caching” capabilities or “memory caching” capabilities. This means that technically virtual machines can use “local flash” resources while the remote resources are “memory” based (or the other way around). I would avoid this at all cost personally though as it will give some strange unpredictable performance result.

So what does this add? Well crazy performance for instance…. We are talking 80k IOps easily with a nice low latency of 50-200 microseconds. Unlike other solutions, FVP doesn’t restrict the size of your cache either. By default it will make a recommendation of 50% unreserved capacity to be used per host. Personally I think this is a bit high, as most people do not reserve memory this will typically result 50% of your memory to be recommended… but fortunately FVP allows you to customize this as required. So if you have 128GB of memory and feel 16GB of memory is sufficient for memory caching then that is what you assign to FVP.
Another feature that will be added is Topology Awareness. Basically what this allows you to do is group hosts in a cluster and create failure domains. An example may make this a bit easier to grasp: Lets assume you have 2 blade chassis each with 8 hosts, when you enable “write back caching” you probably want to ensure that your replica is stored on a blade in the other chassis… and that is exactly what this feature allows you to do. Specify replica groups, add hosts to the replica groups, easy as that!
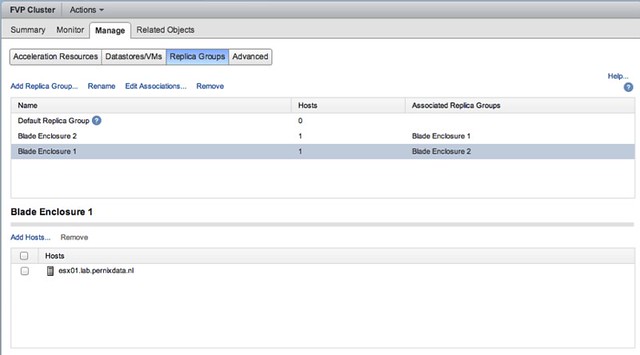
And then specify for your virtual machine where the replica needs to reside. Yes you can even specify that the replica needs to reside within its failure domain if there are requirements to do so, but in the example below the other “failure domain” is chosen.

Is that awesome or what? I think it is, and I am very impressed by what PernixData has announced. For those interested, the SFD video should be online soon, and those who are visiting the Milan VMUG are lucky as Frank mentioned that he will be presenting on these new features at the event. All in all, an impressive presentation again by PernixData if you ask me… awesome set of features to be added soon!
Holy crap! I’ve been following PernixData for quite awhile now and positioning it wherever I can. Now, with these new features it gets even better! Thanks for the write-up Duncan. This company is doing disruptive stuff with flash (and now memory!).
It’s refreshing to see companies that execute well and fast. No need for road maps.
POC of FVP in flight for a month now. Excellent stuff, highly recommended!