Many of us have been logging in to the ESX console for ages and have (ab)used the esxcfg-* commands on a regular basis. We’ve used them in scripts and during troubleshooting and all of that is about to change… vSphere 5.0 introduces a new command line utility: esxcli.
Some of you will say “Hey esxcli was already available before 5.0”, and yes you are correct it was around however it has been completely revamped, it feels different… it is different, hence I said “new”. A unified command is most definitely the direction we are heading in and as such it is of utmost importance that you get familiarized with it. Although the esxcfg-* commands are still available they have been deprecated and as such no longer supported.
What has changed? Well very simple many new name spaces have been introduced and the namespace that were already in there moved up a layer to allow for a more scalable and flexible tool. Under the “root” of esxcli there are the following namespaces:
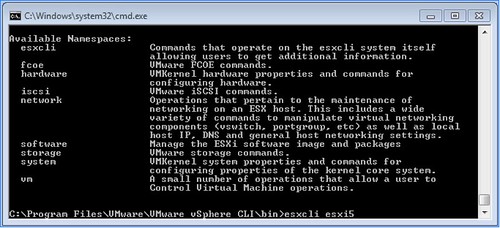
So how are these constructed?
esxcli [dispatcher options] <namespace> [<namespace> …] <cmd> [cmd options]
With dispatcher options we are referring to the ability to connect to a remote host for instance but also with a different username/password. Namespaces is mentioned twice as namespaces can actually be nested and use a drill down approach as I would like to call it. Cmd options refers to the command that needs to be executed to this namespace, this could be “get”, “list” or “set”.
I guess most namespaces actually make a lot of sense. Lets give a couple of example to show the power of esxcli:
- Add a portgroup to a vSwitch –> esxcli network vswitch standard portgroup add –portgroup-name=<portgroup> –vswitch-name=<vSwitch>
- List all storage devices –> esxcli storage nmp device list
- Add a dns-server –> esxcli network ip dns server add –server=<dns server name or ip>
- Add an nfs-share –> esxcli filesystem nfs add –host=<host_name> –share=<share_name> –volume=<volume_name>
- Change MTU of vmkernel interface –> esxcli network ip interface set -m <mtu size> -i <interface_name>
It is all fairly straight forward as you’ve seen, but I have found myself lost in the trenches of esxcli already a couple of times. If this happens to you remember that you can also list all namespaces very simply by doing the following:
- esxcli esxcli command list
For more detailed and in-depth info check this excellent article by William Lam.