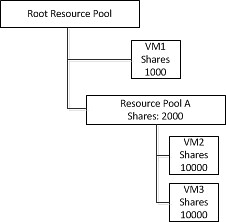
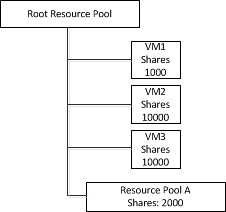
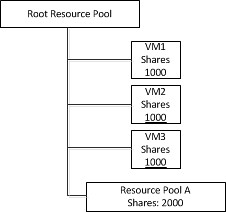
I was reading an excellent article on NetApp metroclusters and vm-host affinity rules Larry Touchette the other day. That article is based on the tech report TR-3788 which covers the full solution but did not include the 4.1 enhancements.
The main focus of the article is on VM-Host Affinity Rules. Great stuff and it will “ensure” you will keep your IO local. As explained when a Fabric Metrocluster is used the increased latency when going across for instance 80KM of fibre will be substantial. By using VM-Host Affinity Rules where a group of VMs are linked to a group of hosts this “overhead” can be avoided.
Now, the question of course is what about HA? The example NetApp provided shows 4 hosts. With only four hosts we all know, hopefully at least, that all of these hosts will be primary. So even if a set of hosts fail one of the remaining hosts will be able to take over the failover coordinator role and restart the VMs. Now if you have up to an 8 host cluster that is still very much true as with a max of 5 primaries and 4 hosts on each side at least a single primary will exist in each site.
But what about 8 hosts or more? What will happen when the link between sites fail? How do I ensure each of the sites has primaries left to restart VMs if needed?
Take a look at the following diagram I created to visualize all of this:
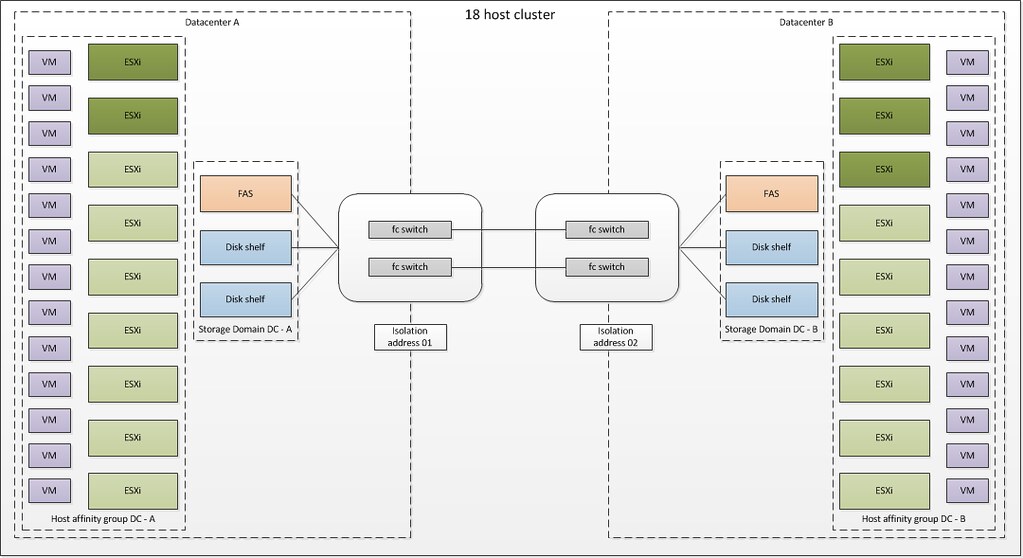
We have two datacenters here, Datacenter A and B. Both have their own FAS with two shelves and their own set of VMs which run on that FAS. Although storage will be mirrored there is still only one real active copy of the datastore. In this case VM-Host Affinity rules have been created to keep the VMs local in order to avoid IO going across the wire. This is very much similar to what NetApp described.
However in my case there are 5 hosts in total which are a darker color green. These hosts were specified as the preferred primary nodes. This means that each site will have at least 2 primary nodes.
Lets assume the link between Datacenter A and B dies. Some might assume that this will trigger an HA Isolation Response but it actually will not.
The reason for this being is the fact that an HA primary node still exists in each site. Isolation Response is only triggered when no heartbeats are received. As a primary node sends a heartbeat to both the primary and secondary nodes a heartbeat will always be received. Again as I can’t emphasize this enough, an Isolation Response will not be triggered.
However if the link dies between these Datacenter’s, it will appear to Datacenter A as if Datacenter B is unreachable and one of the primaries in Datacenter A will initiate restart tasks for the allegedly impacted VMs and vice versa. However as the Isolation Response has not been triggered a lock on the VMDK will still exist and it will be impossible to restart the VMs.
These VMs will remain running within their site. Although it might appear on both ends that the other Datacenter has died HA is “smart” enough to detect it hasn’t and it will be up to you to decide if you want to failover those VMs or not.
I am just so excited about these developments, that I can’t get enough of it. Although the “das.preferredprimaries” setting is not supported as of writing, I thought this was cool enough to share it with you guys. I also want to point out that in the diagram I show 2 isolation addresses, this of course is only needed when a gateway is specified which is not accessible at both ends when the network connection between sites is dead. If the gateway is accessible at both sites even in case of a network failure only 1 isolation address, which can be the default gateway, is required.