I was reading an excellent article on NetApp metroclusters and vm-host affinity rules Larry Touchette the other day. That article is based on the tech report TR-3788 which covers the full solution but did not include the 4.1 enhancements.
The main focus of the article is on VM-Host Affinity Rules. Great stuff and it will “ensure” you will keep your IO local. As explained when a Fabric Metrocluster is used the increased latency when going across for instance 80KM of fibre will be substantial. By using VM-Host Affinity Rules where a group of VMs are linked to a group of hosts this “overhead” can be avoided.
Now, the question of course is what about HA? The example NetApp provided shows 4 hosts. With only four hosts we all know, hopefully at least, that all of these hosts will be primary. So even if a set of hosts fail one of the remaining hosts will be able to take over the failover coordinator role and restart the VMs. Now if you have up to an 8 host cluster that is still very much true as with a max of 5 primaries and 4 hosts on each side at least a single primary will exist in each site.
But what about 8 hosts or more? What will happen when the link between sites fail? How do I ensure each of the sites has primaries left to restart VMs if needed?
Take a look at the following diagram I created to visualize all of this:
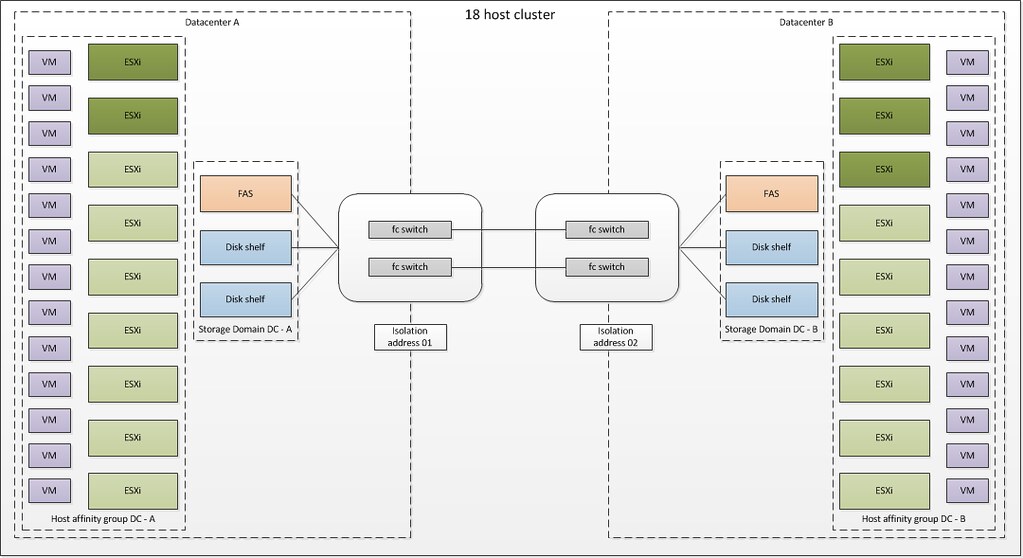
We have two datacenters here, Datacenter A and B. Both have their own FAS with two shelves and their own set of VMs which run on that FAS. Although storage will be mirrored there is still only one real active copy of the datastore. In this case VM-Host Affinity rules have been created to keep the VMs local in order to avoid IO going across the wire. This is very much similar to what NetApp described.
However in my case there are 5 hosts in total which are a darker color green. These hosts were specified as the preferred primary nodes. This means that each site will have at least 2 primary nodes.
Lets assume the link between Datacenter A and B dies. Some might assume that this will trigger an HA Isolation Response but it actually will not.
The reason for this being is the fact that an HA primary node still exists in each site. Isolation Response is only triggered when no heartbeats are received. As a primary node sends a heartbeat to both the primary and secondary nodes a heartbeat will always be received. Again as I can’t emphasize this enough, an Isolation Response will not be triggered.
However if the link dies between these Datacenter’s, it will appear to Datacenter A as if Datacenter B is unreachable and one of the primaries in Datacenter A will initiate restart tasks for the allegedly impacted VMs and vice versa. However as the Isolation Response has not been triggered a lock on the VMDK will still exist and it will be impossible to restart the VMs.
These VMs will remain running within their site. Although it might appear on both ends that the other Datacenter has died HA is “smart” enough to detect it hasn’t and it will be up to you to decide if you want to failover those VMs or not.
I am just so excited about these developments, that I can’t get enough of it. Although the “das.preferredprimaries” setting is not supported as of writing, I thought this was cool enough to share it with you guys. I also want to point out that in the diagram I show 2 isolation addresses, this of course is only needed when a gateway is specified which is not accessible at both ends when the network connection between sites is dead. If the gateway is accessible at both sites even in case of a network failure only 1 isolation address, which can be the default gateway, is required.
(Disclosure: I work for EMC.)
Good article, Duncan. I’d like to point out that this sort of configuration is applicable to any product that can create stretched clusters, not just NetApp MetroCluster. The same sort of configuration, using DRS host affinity rules and the “das.preferredprimaries” setting, would be equally applicable to an EMC VPLEX Metro configuration.
Do you have a timeframe or any word on official support of the “das.preferredprimaries” setting?
Thanks!
I asked that yesterday and I can’t give a timeframe officially or unofficially for that matter unfortunately.
Indeed, this applies to other storage vendors as well who offer stretched clusters. In this case I mentioned NetApp as they have excellent docs out in the open about it.
Again, disclosure EMCer here…. Very apropos and amazing timing
We have a draft VMware KB we’re trying to cross the T’s and dot the I’s on re exactly this behavior with VPLEX 🙂
Draft has been submitted to VMware (Henry R’s team, Duncan) – will be a fun VMworld!!!
There’s also a lot of work underway to:
1) Add these stretched configurations to the VMware HCL as it’s a growing category (including both active/passive models and active/active models) – currently there isn’t a formal test suite for it, NetApp, EMC (and others) forging new ground with our VMware colleagues.
2) Change some behavior to make the use case more of a “rock” in future vSphere releases – around the VM HA primary selection and changing some of the partition behavior and start sequencing (ping me out of band, Duncan, and I’ll give you the poop – no public discussions of futures, I get in big trouble).
Fun stuff!
Toss my hat into the ring for HCL support of stretched storage domains as well. This is something that I’ve got customers interested in (disclosure: we’re an HP and EMC partner), so EMC VPLEX or HP SVSP stretched domains for these multi-datacenter solutions. Official support for something like “das.preferredprimaries” is of great interest to us, too. 🙂
… already possible with an IPSTOR NSS cluster and working ever with netapp or EMC machines.
@DS45 — from a storage perspective, we can do this with SVSP and VPLEX as well. The issue, as @Duncan mentions, is with the vSphere platform’s HA and DRS functionality. I think these are relevant regardless of the storage backend since they are architectural considerations.
Doug, i agree, but with cluster like IPSTOR, all the storage is in a single domain so your VMs are working in a single site (even if your like me in an extend fabric 19Km large 8 hosts in each part …) So it’s HA rules that will prevent starting of the VM in an isolation case. And that’s why i put SRM over to start manually VMs i would need on the other side.
Great article, but i have one problem understanding how the locking stuff works:
There are 3 possible scenarios:
1) A host in datacenter A is really down. What happens to the locks it held for the VMs that were running on this host ? Are they actively removed by a primary host when the host is detected as dead ? Are they aging out ? Is the lock gone when the host is gone ?
2) A host is isoltated, it stops the vm’s and deletes the locks. For the other hosts, there are no locks anymore, so the vm can be restarted on another host
3) The connection between the datacenter dies : HA in datacenter A detects that all the hosts in datacenter B are dead and tries to restart the VM’s on hosts in datacenter A. As you write this does not happen, because the locks still exist.
How can scenario 1 and 3 work together ? Anybody has to remove the lock.
If the locks are aging out, the locks on the filer on the remote site will age out, too. So HA should be able to start the VMs in datacenter B – Fail
It a host actively holds a lock, it can’t hold it on the filer on the remote site -> lock gone -> HA starts the machines on the remote site – Fail
Am i missing something ?
Thanks
Kai
Way cool Duncan. From the looks of this you came up with that diagram on your own? You have mad visio skills… or maybe just placement logic. Mine always look like spaghetti with lines everywhere.
@Stever
The only way for perceived situation you speak of to happen is if the network connectivity between the two datacenters was not working and a host failed during the outage — unlikely. Possible though, especially if it were a power issues.
The locks on a VM’s vmdks will be removed when the host you mention dies, so VMs could be restarted on either side. This assumes the fiber connectivity remained intact even though the ethernet did not. One side would be first to restart any one particular VM and the locks would again be there preventing the otherside from starting (it might be interesting to see how restart priorities played into that). It obviously couldn’t start in both places, and if the fiber connectivity was lost between sites then it could only start on the side where hosts were still connected to the active datastore.
The more likely scenario when a host dies would be that the network and fiber connectivity is still working between sites. In that case a primary node coordinates the failover and the VM(s) would restart without any issues since everyone can jibber-jabber as one happy family. I assume at somepoint after the restart that DRS would enforce the host affinity rules if any of the VMs started up on the opposite side. Every thing in the mushroom kingdom would be normal again outside of your server that exploded. Stupid physical server ;).
See, no problems :).
@stever , when a host completely fails the lock in the vmdk will time out. As such it will enable the remaining nodes to restart the VM’s.
Duncan
Do the esx hosts need to be connected to the metro cluster via FC or will this work over iscsi?