** Disclaimer: This is for educational purposes, please don’t implement this in your production environment as it is not supported! **
Last week I received a question and I figured I would dive in to it this week. The question was if it is possible to fail-over LUNs using VMware Site Recovery Manager (SRM) which are not part of the Cluster which SRM “manages”. In other words, can I fail-over a LUN which is attached to a physical Windows Server or to a completely separate VMware Cluster? Before we continue, I did not hack SRM itself, neither did I make any changes to the SRA.
Lets briefly explain what SRM does normally when you go through the process of of creating a DR plan. Now this is slimmed down with only focussing on the relevant stuff for this question:
- First it will discover the devices using the Storage Replication Adapter (SRA)
- It then discovers all LUNs using the SRA
- It show the replicated LUNs containing VMs to the admin
- Admin can use these in his plan and “protect” the VMs appropriately
I decided to install SRM in a nested environment using the Celerra Uber VSA. I installed the VNX SRA and configured it and went through some of the log files just to find a piece of evidence that my plan is even possible. For Windows 2008 you can find the SRM Log Files in this location by the way:
%ALLUSERSPROFILE%\VMware\VMware vCenter Site Recovery Manager\Logs\
Other locations are documented in this KB. When I created the environment I created multiple LUNs with different sizes to make them easily recognizable. The LUN which is replicated but not exposed to our vCenter/SRM environment is 25GB and the LUN which is exposed is 30GB. This is what the log files showed me when I did a quick find on the size:
(Production) fsid=14 size=30000MB alloc=0MB dense read-write path=/srm01/fs14_T1_LUN1_BB005056AE32800000/fs14_T1_LUN1_BB005056AE32800000 (snapped)
(Production) fsid=16 size=25000MB alloc=0MB dense read-write path=/vc01/fs16_T1_LUN2_BB005056AE32800000/fs16_T1_LUN2_BB005056AE32800000 (snapped)
As you can see both my 25GB and my 30GB LUN is listed. I added a name to it which also allows me to quickly identify it “srm01” and “vc01”, where “vc01” is the one which is not managed by SRM.
So how does SRM get this information? Well it is actually pretty straight forward, SRM calls a script which is part of the SRA. SRM feeds this script XML. This XML code contains the commands / details required. I’ve written about this a long time ago when I was troubleshooting SRM and it is still applicable:
perl command.pl < file.xml
Now the XML file is of course key here… How does that need to be structured and can we use, or should I say abuse, it to do a fail-over of a LUN which is not “managed” by SRM/vCenter. Well I started digging and it turns out to be fairly straight forward. Keep in mind the disclaimer at the top though, this is not what the SRA’s were intended for… this is purely for educational purposes and far from supported. Again the logfiles exposed a lot of details here, but I stripped it down to make it readable. This is the response from the SRA when SRM asked for details on which devices are available:
2012-01-09T12:14:53.583-08:00 [05388 verbose 'SraCommand' opID=7D6C5634-00000023] discoverDevices responded with: --> <?xml version="1.0" encoding="UTF-8" standalone="yes"?> --> <SourceDevice state="read-write" id="1-1"> --> <Name>fs14_T1_LUN1_BB005056AE32800000</Name> --> <Identity> --> <Wwn>60:06:04:8c:ab:b2:88:c0:59:40:72:24:1b:5f:77:72</Wwn> --> </Identity> --> <TargetDevice key="fs14_T1_LUN1_BB005056AE32800000_fs10_T1_LUN1_BB005056AE32820000"/> --> </SourceDevice> --> <SourceDevice state="read-write" id="1-2"> --> <Name>fs16_T1_LUN2_BB005056AE32800000</Name> --> <Identity> --> <Wwn>60:06:04:8c:b8:50:22:96:0c:0b:bf:d8:59:0b:a1:75</Wwn> --> </Identity> --> <TargetDevice key="fs16_T1_LUN2_BB005056AE32800000_fs12_T1_LUN3_BB005056AE32820000"/> --> </SourceDevice> --> </SourceDevices>
Now if you look at SRM and try to make a Protection Group plan you will quickly discover that only those Datastores which have a VM hosted on there can be added. This is shown in the screenshot below.
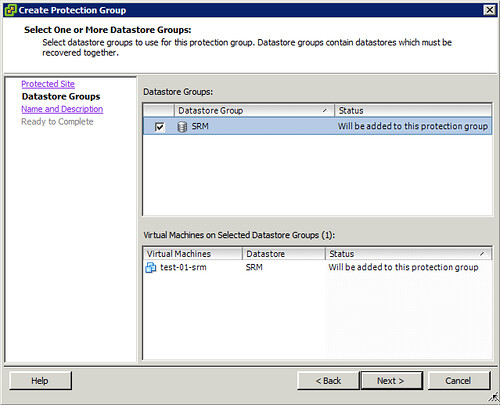
As mentioned SRM filters out the “irrelevant LUNs”, to me this LUN wasn’t irrelevant however. So what’s next? I decided to initiated a fail-over and to look at the log files. When the fail-over is initiated the following is issued by SRM, again I stripped some details to make it more readable:
--> <FailoverParameters> --> <ArrayId>BB005056AE32820000-server_2</ArrayId> --> <AccessGroups> --> <AccessGroup id="domain-c7"> --> <Initiator id="iqn.1998-01.com.vmware:localhost-11616041" type="iSCSI"/> --> <Initiator id="iqn.1998-01.com.vmware:localhost-4a15366e" type="iSCSI"/> --> <Initiator id="10.21.68.106" type="NFS"/> --> <Initiator id="10.21.68.105" type="NFS"/> --> </AccessGroup> --> </AccessGroups> --> <TargetDevices> --> <TargetDevice key="fs14_T1_LUN1_BB005056AE32800000_fs10_T1_LUN1_BB005056AE32820000"> --> <AccessGroups> --> <AccessGroup id="domain-c7"/> --> </AccessGroups> --> </TargetDevice> --> </TargetDevices> --> </FailoverParameters>
I guess we should be able to work with this! Using the “discoverdevices” information and combining it with the “Failover” information I should be able to construct my own custom XML file. After creating this XML file I should be able to fail-over any LUN which is part of the selected device… What is my plan? I am planning to change the following:
- Initiator id
- TargetDevice key
I wasn’t sure if I needed to change the AccessGroup so I figured I would just test it like this. I called the script as follows:
<path to perl>\bin\perl.exe command.pl < file.xml
I watched a whole bunch of messages pass by and then looked at the Celerra when then fail-over commend was completed and noticed the following:

And of course within the “unmanaged” vCenter you can see it:

Successful fail-over of a LUN which wasn’t part of an SRM Protection Group! Yes, when you replace the Initiator ID even the masking is correctly configured. The only thing left would be either resignaturing the volume or mounting the volume. This of course depends on the OS owning the volume and the desired end result. All in all, a nice little experiment… Once again, don’t try this in your own environment, it is far from supported!