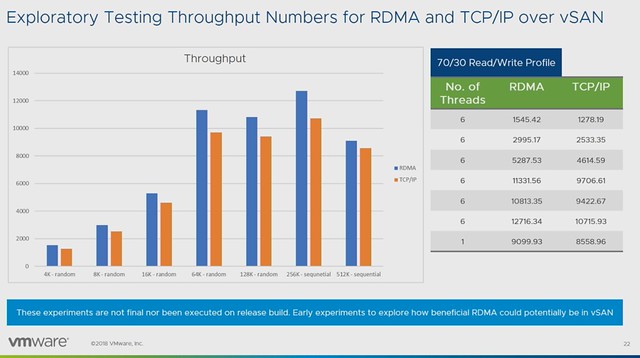
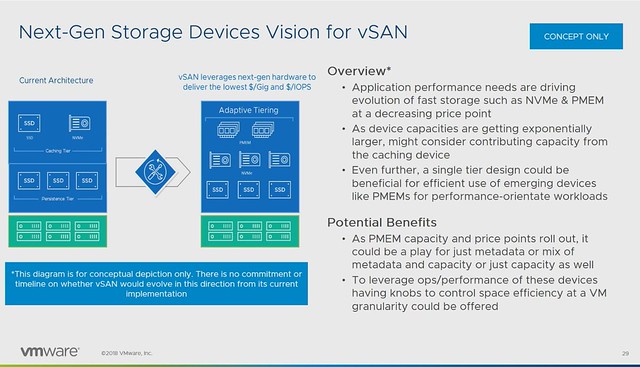
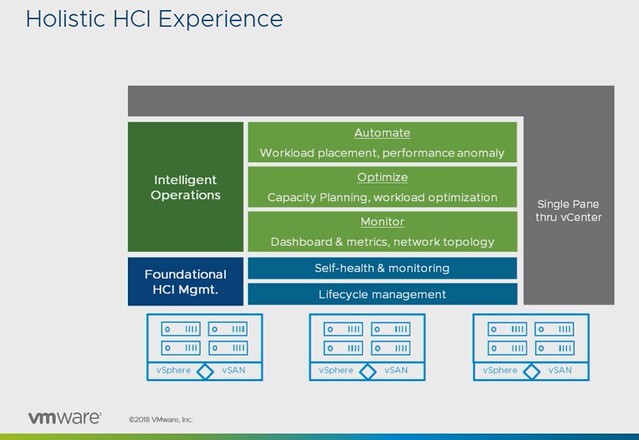
This is the last post in this VMworld Sessions series. Although the title lists “CTO3509BU: Embracing the Edge: Automation, Analytics, and Real-Time Business” which is by Chris Wolf and Daniel Beveridge, I would also highly recommend watching Daniel’s other session titled “CTO2161BU Smart Placement of Workloads in Tomorrow’s Distributed Cloud“. Both sessions discuss a similar topic and this Edge vs Cloud and where workloads and data should be placed. Both very interesting topics if you ask me, and definitely topics I am starting to explore more.
Chris discussed the various use cases around Edge Computing and the Technology Drivers, some of these very obvious but some of them not so much. What often is skipped is the business continuity aspect of edge but also things like network costs, limitations, and even data gravity. It is good to see that Chris addressed these. Some people still seem to be under the impression that every workload can run in the cloud, but in many cases it simply isn’t possible to send data to the cloud. Could be that the volume is too high, could be that the time it takes to transfer and analyze is too long (transaction execution time), or maybe it is physically impossible. It could also be that the application is mission-critical, meaning that the service can’t rely on a connection to the internet.

As a company, VMware is aiming to provide a solution for Edge and IoT, yet work closely with the very rich partner ecosystem and the main focus is providing a “native experience” for developers. Which provides customers choice as it avoids lock-in. Now I don’t want to start a lock-in discussion here as one could claim that it is difficult to migrate between platforms, and this is always the case, if not only because of the operational aspects (tooling/processes). A diagram which explains the different initiatives was then presented, and I like this diagram a lot as it differentiates between “device edge” and “compute edge”, on top of that it shows a differentiation between the device edge focussed on things vs people (big difference).

Next discussed is IoT management, Chris explains how Pulse 2.0 will be capable of managing up to 500 million managed objects. Pulse provides central management across different IoT device manufacturers. Instead of having a point solution for each manufacturer we introduced an abstraction layer and automate things like updates etc. (Sounds familiar?) Then ESXi for ARM is briefly touched upon, as Christ mentioned this is not for general purpose intended. VMware is looking for very specific use cases, if you are one of those partners/customers that has a use case for ESXi on ARM then please reach out to us and let’s discuss the use case and opportunity!
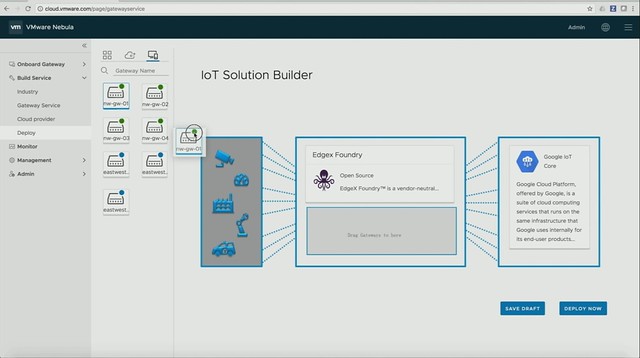
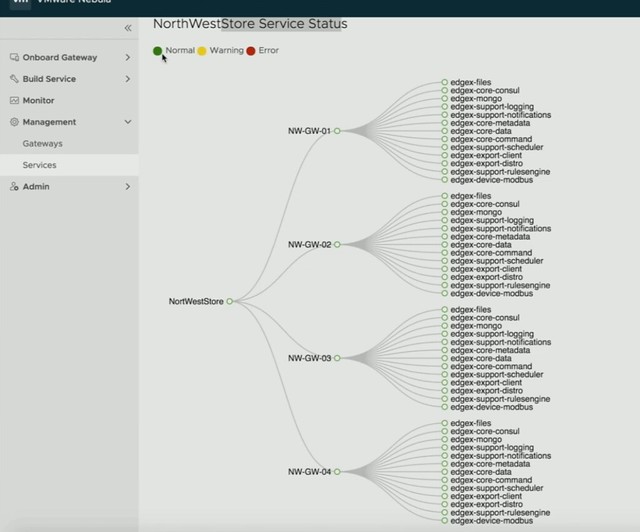
First, a new project is introduced by Daniel, it is called Project Nebula. Nebula brings an IoT marketplace, in this marketplace you can select various IoT services (which come in the form of containers), which are then sent to the IoT gateways. It looks pretty cool, as Daniel shows how he simply pushed various IoT services down to capable IoT gateways. So there’s a validation there if the edge services can run on the specific devices. On top of that, a connection to specific cloud services can also be provided so that certain metrics can be send up and analyzed when needed. Pretty smooth, I also like the fact that it provides monitoring, even down to the sensor and individual service as shown in the second screenshot below.
Next, it is briefly discussed why vSphere/VMware is the right platform, and then they jump into the momentum there is around cloud services and edge computing today. A brief overview of Amazon RDS on VMware is given and more importantly why this is a valuable solution, especially the replication of instances from on-premises to cloud and across regions. Of course, AWS Greengrass is mentioned, VMware also has a story in this space. You can run Greengrass on-premises in a highly available manner and it is dead simple to implement. For those who have not seen the announcements around that, read up here. Next Chris and Daniel go over various use cases, I guess Daniel likes wine as he explains how a Winery leverages AWS Lamba and Greengrass to analyze data coming from sensors which then drives control systems. On top of that, based on customer (and sommelier) ratings of wine, leveraging the data provided by sensors and matching that with customer behavior the winery can predict which barrels will score higher and most likely sell better etc. Very interesting story.
Compute edge is discussed next, this is where project dimension comes in to play, however first Chris defines the difference between the different option people have for consuming certain services. When does Cloud, Compute or Device Edge make sense? It is all about “time” or “latency”, how fast do you or the process need a response from the system? Transaction time window within 500ms and latency lower than 5ms? Well then you need to process at “device edge layer”, if a transaction time of below 1s is acceptable and latency of around 20ms then the “compute edge would work. Is a transaction time of larger than 1s okay and latency of higher than 20ms, then the cloud may be an option. As I said, it all revolves around how long you can wait.
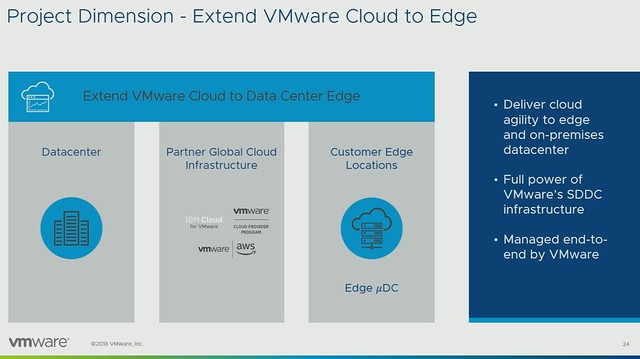
Project Dimension delivers a compute edge solution which runs on-premises but is managed by VMware and delivered as a service. What I also liked is that the “micro” and “nano” data center is discussed, meaning that there potentially will be an option in the future to buy small form factor solutions which allow you to run a handful of VMs. More importantly, these solutions will consume less power and require less cooling. These things can make a big difference, especially as many Edge locations don’t have a data center room. Again ESXi for ARM is mentioned, this sounds very interesting, would be interesting to see if there are plans to mix this with Project Dimension over time, but that is just me thinking out loud.
From a networking perspective of course VeloCloud is discussed, and some very cool projects where cloud networks can be utilized and per traffic type certain routes can be used based on availability and performance (I probably should say QoS).
That was it for now as I don’t want to type out the whole session verbatim, for more specifics please watch the two sessions, worth your time, TO3509BU: Embracing the Edge: Automation, Analytics, and Real-Time Business” and/or “CTO2161BU Smart Placement of Workloads in Tomorrow’s Distributed Cloud“.