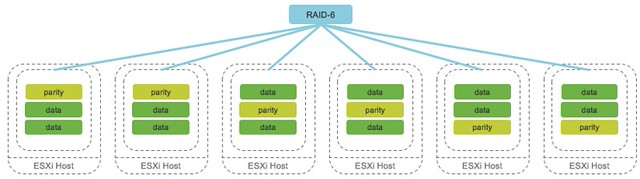
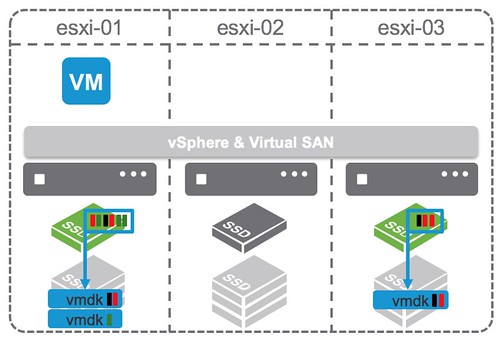
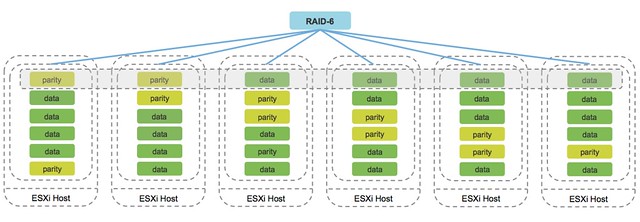
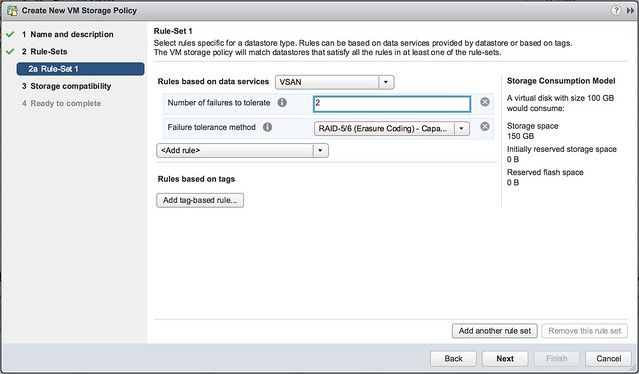
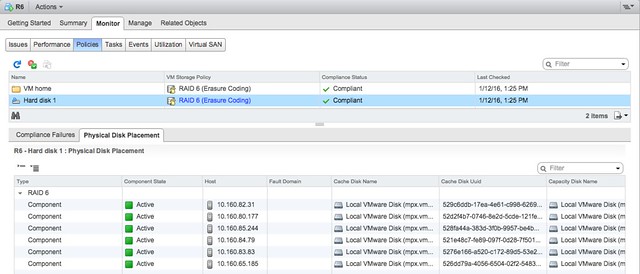
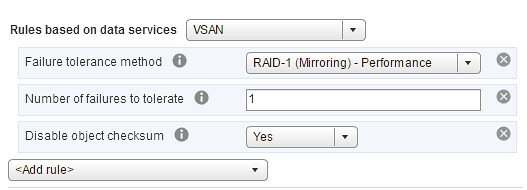
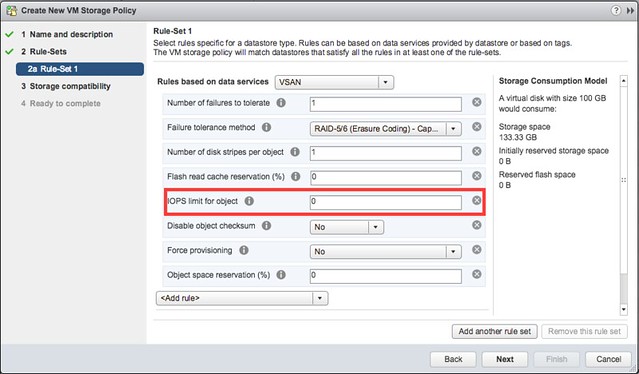
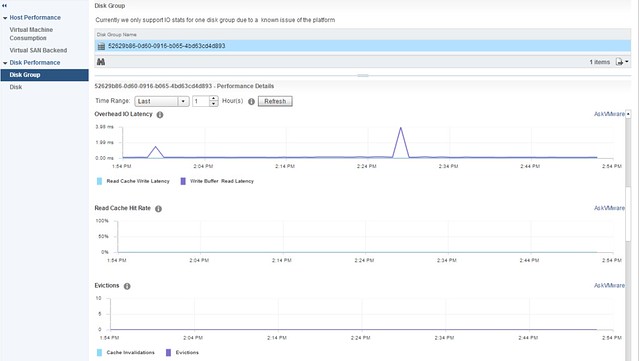
I’ve been discussing this over the last 12 months with Frank, and to be honest we are still not sure what is the right thing to do but we decided to take this step anyway. Over the past couple of years we released various updates of the vSphere Clustering Deepdive. Updating the book sometimes was a massive pain (version 4 to 5 for instance), but some of the minor updates have been relative straight forward, although still time consuming due to formatting / diagrams / screenshots etc.
Ever since we’ve been looking for new ways to distribute our book, or publication as I will refer to it from now on. I’ve looked at various options, and found one which I felt was the best of all worlds: Gitbook. Gitbook is a solution which allows you as an author to develop content in Markdown and distribute it in various different formats. This could be as static html, pdf, ePub or Mobi. Basically any format you would want in this day and age. The great thing about the platform as well is that it integrates with Github and you can share your source there and do things like version control etc. It does it in such a way that I can use the Gitbook client on my Mac, while someone else who wants to contribute or submit a change can simply use their client of choice and submit a change through git. Although I don’t expect too many people to do this, it will make it easier for me to have material reviewed for instance by one of the VMware engineers.
So what did I just make available for free? Well in short, an updated version (vSphere 6.0 Update 1) of the vSphere HA Deepdive. This includes the stretched clustering section of the book. Note that DRS and SDRS have not been included (yet). This may or may not happen in some shape or form in the future though. For now, I hope you will enjoy and appreciate the content that I made available for free. You can access it by clicking “HA Deepdive” on the left, or (in my opinion) for a better reading experience read it on Gitbook directly through this link: ha.yellow-bricks.com.
Note that there are links as well to download the content in different formats, for those who want to read it on their iPad / phone / whatever. Also note that Gitbook allows you to comment on a paragraph by clicking the “+” sign on the right side of the paragraph when you hover over it… Please submit feedback when you see mistakes! And for those who are really active, if you want to you could even contribute to the content! I will keep updating the content over the upcoming months probably with more info on VVols and for instance the Advanced Settings, so keep checking back regularly!