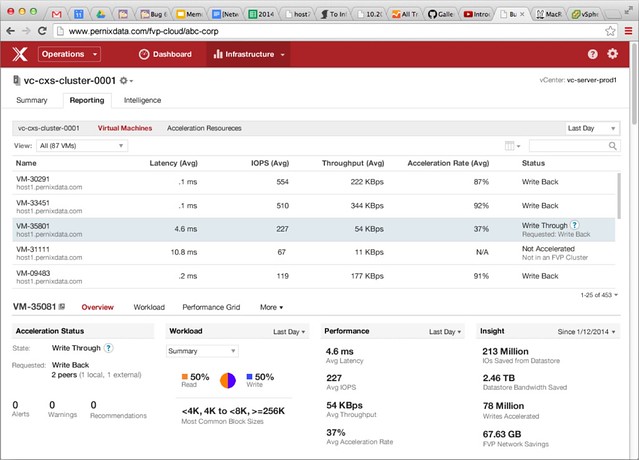
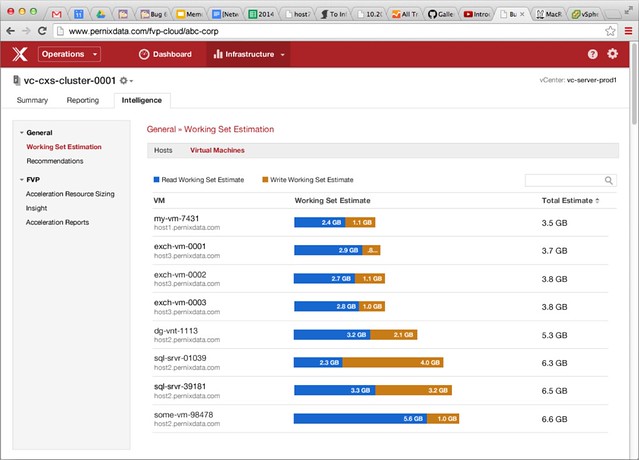
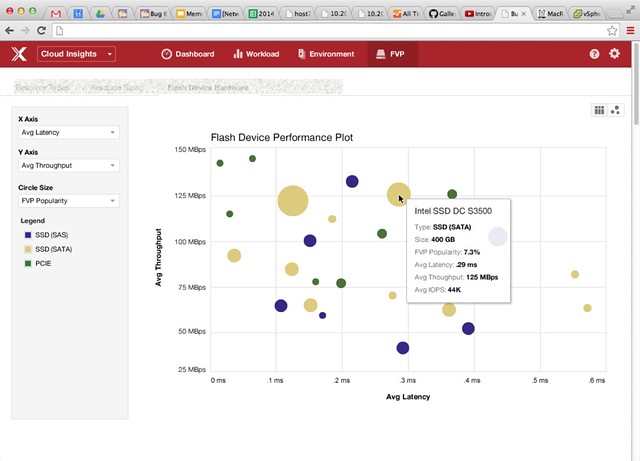
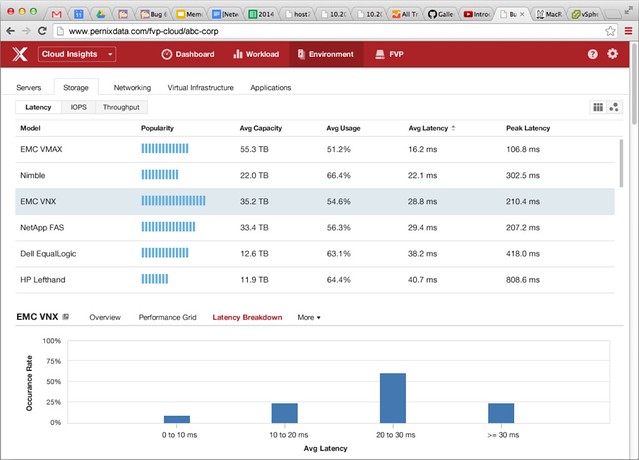
I’d already blogged about this on the VMware blog, but I figured I would share it here as well. The vSphere Metro Storage Cluster with vSphere 6.0 white paper has been released. I worked on this paper together with my friend Lee Dilworth, it is an updated version of the paper we did in 2012. It contains all of the new best practices for vSphere 6.0 when it comes to vSphere Metro Storage Cluster implementations, so if you are looking to implement one or upgrade an existing environment make sure to read it!
VMware vSphere Metro Storage Cluster Recommended Practices
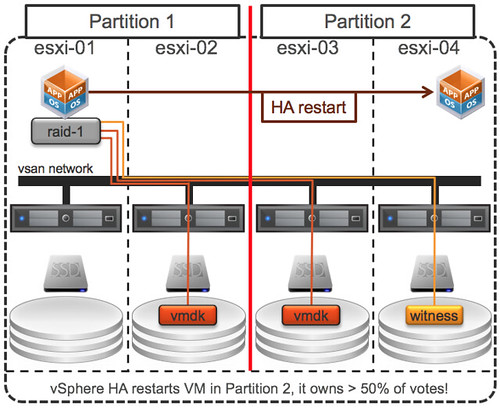
VMware vSphere Metro Storage Cluster (vMSC) is a specific configuration within the VMware Hardware Compatibility List (HCL). These configurations are commonly referred to as stretched storage clusters or metro storage clusters and are implemented in environments where disaster and downtime avoidance is a key requirement. This best practices document was developed to provide additional insight and information for operation of a vMSC infrastructure in conjunction with VMware vSphere. This paper explains how vSphere handles specific failure scenarios, and it discusses various design considerations and operational procedures. For detailed information about storage implementations, refer to documentation provided by the appropriate VMware storage partner.
 This week I had the pleasure of talking to fellow dutchy
This week I had the pleasure of talking to fellow dutchy  The conversation of course didn’t end there, lets get in to some more details. We discussed the use case first. PeaSoup is a hosting / cloud provider. Today they have two clusters running based on Virtual SAN. They have a management cluster which hosts all components needed for a vCloud Director environment and then they have a resource cluster. The great thing for PeaSoup was that they could start out with a relatively low investment in hardware and scale fast when new customers on-board or when existing customers require new hardware.
The conversation of course didn’t end there, lets get in to some more details. We discussed the use case first. PeaSoup is a hosting / cloud provider. Today they have two clusters running based on Virtual SAN. They have a management cluster which hosts all components needed for a vCloud Director environment and then they have a resource cluster. The great thing for PeaSoup was that they could start out with a relatively low investment in hardware and scale fast when new customers on-board or when existing customers require new hardware. Harold pointed out that the only down side of this particular Fujitsu configuration was the fact that it only came with a disk controller that is limited to “RAID O” only, no passthrough. I asked him if they experienced any issues around that and he mentioned that they had 1 disk failure so far and that is resulted in having to reboot the server in order to recreate a RAID-0 set for that new disk. Not too big of a deal for PeaSoup, but of course if possible he would prefer to prevent this reboot from being needed. The disk controller by the way is based on the LSI 2208 chipset and it is one of things PeaSoup was very thorough about, making sure it was supported and that it had a high queue depth. The “HCL” came up multiple times during the conversation and Harold felt that although doing a lot of research up front and creating a scalable and repeatable architecture takes time, it also results in a very reliable environment with predictable performance. For a cloud provider reliability and user experience is literally your bread and butter, they couldn’t afford to “guess”. That was also one of the reasons they selected a VSAN Ready Node configuration as a foundation and tweaked where their environment and anticipated workload would require it.
Harold pointed out that the only down side of this particular Fujitsu configuration was the fact that it only came with a disk controller that is limited to “RAID O” only, no passthrough. I asked him if they experienced any issues around that and he mentioned that they had 1 disk failure so far and that is resulted in having to reboot the server in order to recreate a RAID-0 set for that new disk. Not too big of a deal for PeaSoup, but of course if possible he would prefer to prevent this reboot from being needed. The disk controller by the way is based on the LSI 2208 chipset and it is one of things PeaSoup was very thorough about, making sure it was supported and that it had a high queue depth. The “HCL” came up multiple times during the conversation and Harold felt that although doing a lot of research up front and creating a scalable and repeatable architecture takes time, it also results in a very reliable environment with predictable performance. For a cloud provider reliability and user experience is literally your bread and butter, they couldn’t afford to “guess”. That was also one of the reasons they selected a VSAN Ready Node configuration as a foundation and tweaked where their environment and anticipated workload would require it.