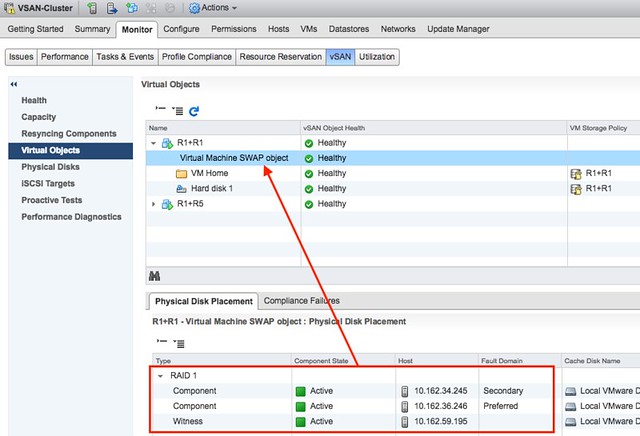
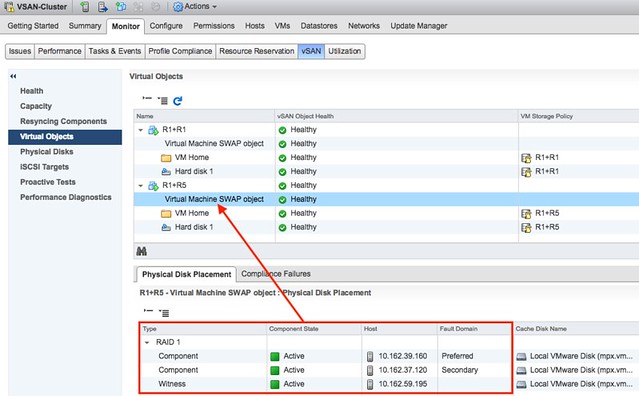
Over the past couple of weeks Cormac Hogan and I have been updating various Core Storage white papers which had not been touched in a while for different reasons. We were starting to see more and more requests come in for update content and as both of used to be responsible for this at some point in the past we figured we would update the papers and then hand them over to technical marketing for “maintenance” updates in the future.
You can expect a whole series of papers in the upcoming weeks on storagehub.vmware.com and the first one was just published. It is on the topic of the vSphere APIs for I/O Filtering and provides an overview of what it is, where it sits in the I/O path and how you can benefit from it. I would suggest downloading the paper, or reading it online on storagehub: