When I just woke up I saw the news was out… A new round of funding for CloudPhysics! CloudPhysics raised $15 million in a series C investment round, bringing the company’s total funding to $27.5 million! Congratulations folks, I can’t wait to see what this new injection will result in to. One of the things that CloudPhysics heavily invested in to the past 12 months has been the storage side of the house. In their SaaS based solution one of the major pillars today is Storage Analytics, along side General Health Checks and Simulations.
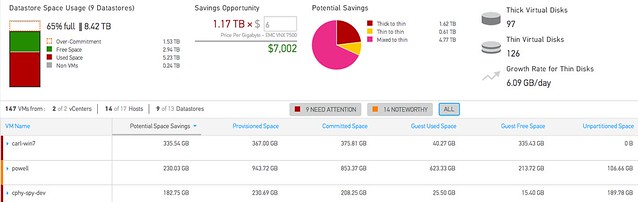
The Storage Analytics section is available as of today to everyone out there! It will allow you to monitor things like “datastore contention”, “unused VMs” and everything there is to know about capacity savings ranging from inside the guest to datastore level details. If you ever wondered how “big data” could be of use to you, I am sure you will understand when you start using CloudPhysics. Not just their monitoring and simulation cards are brilliant, the Card Builder is definitely one of their hidden gems. If you need to convince your management, than all you should do is show the above screenshot: savings opportunity!
Of course there is a lot more to it than I will be able to write about in this short post. In my opinion if you truly want to understand what they bring to the table, just try it out for free for 30 days here!
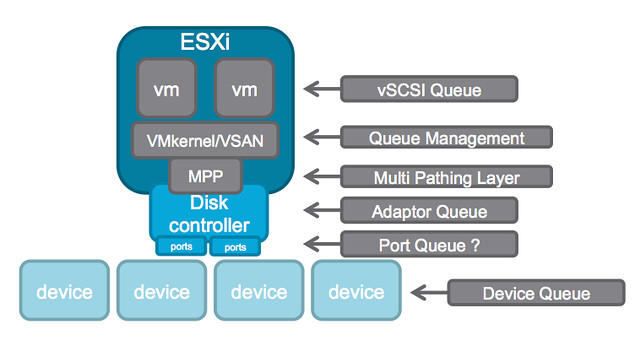
PS: How about this brilliant Infographic… from the people who taught you how to fight the noisy neighbour, they now show you how to defeat that bully!

**disclaimer: I am an advisor to CloudPhysics **