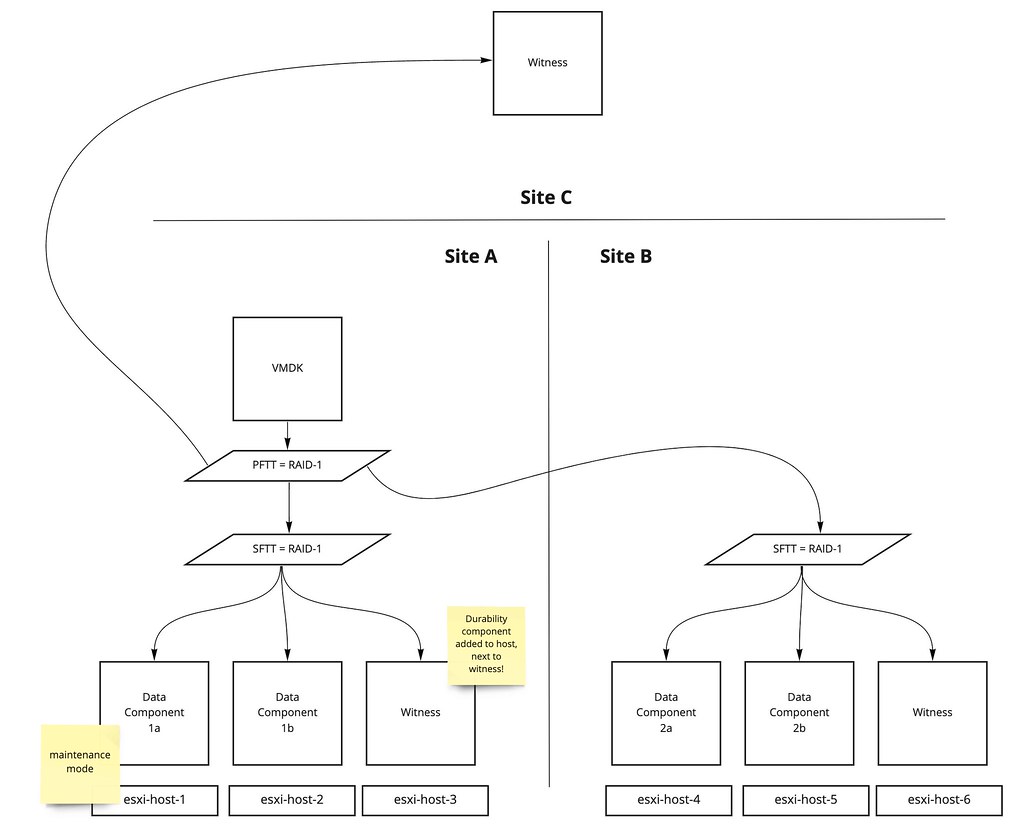
I had two comments on my HCI Mesh compute only blogpost where both were reporting the same error when trying to mount a remote datastore. The error that popped up was the following:
Failed to run the remote datastore mount pre-checks.
I tried to reproduce it in my lab, as both had upgraded from 7.0 to U2 I did the same, that didn’t result in the same error though. The error doesn’t provide any details around why the pre-check fails, as shown below in the screenshot. After some digging I found out that the solution is simple though, you need to make sure IPv6 is enabled on your hosts. Yes, even when you are not using IPv6, it still needs to be enabled to pass the pre-checks. Thanks, Jiří and Reza for raising the issue!