No, I am not exaggerating. Alan Renouf truly is the uncrowned king of PowerCLI. Although I’ve seen some amazing scripts from other people as well Alan always seems to bring that little extra to make him stand out. No this is not an Alan Renouf appreciation blog article, although he deserves one, this article is about his two latest additions.
The first one is the Virtu-Al VESI & PowerGui Powerpack. If you are like me, not a powercli hero, this is what you were looking for all along. Alan has bundled all his script into a Powerpack which enables you to import all his scripts at once and run them with a single click. All scripts are placed into categories which makes them easy to find. Not only can you use them you can also modify them to your needs. Of course if you do improve these scripts give some feedback to Alan so that he might be able to incorporate it into the Powerpack.
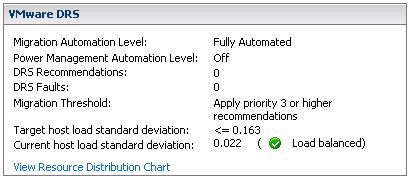
The second one is Version 3 of the daily report or vCheck as it is called as of v3. I wrote about version 1 and many people have downloaded it and are using it in their environment. The script just got better and a whole set of new features have been added. Alan was smart enough to ask around in the community what his report was lacking and incorporated all these tips in Version 3 of vCheck(previously known as the Daily Report). Again, if you feel there is anything missing don’t hesitate to leave a comment and ask Alan if he can add it… Here’s the list of new features:
- Status report to screen whilst running interactively
- At the top of the script you can now turn off any areas you do not want to report on (this makes it faster to run)
- VMs on Local storage has been changed to report VMs stored on datastores attached to only one host
- VM active alerts
- Cluster Active Alerts
- If HA Cluster is set to use host datastore for swapfile, check the host has a swapfile location set
- Host active Alerts
- Dead SCSI Luns
- VMs with over x amount of vCPUs
- vSphere check: Slot Sizes
- vSphere check: Outdated VM Hardware (Less than V7)
- VMs in Inconsistent folders (the name of the folder is not the same as the name)
- Added the number of issues to each title line
Carter can you please hand over your crown to Alan?! Thanks,