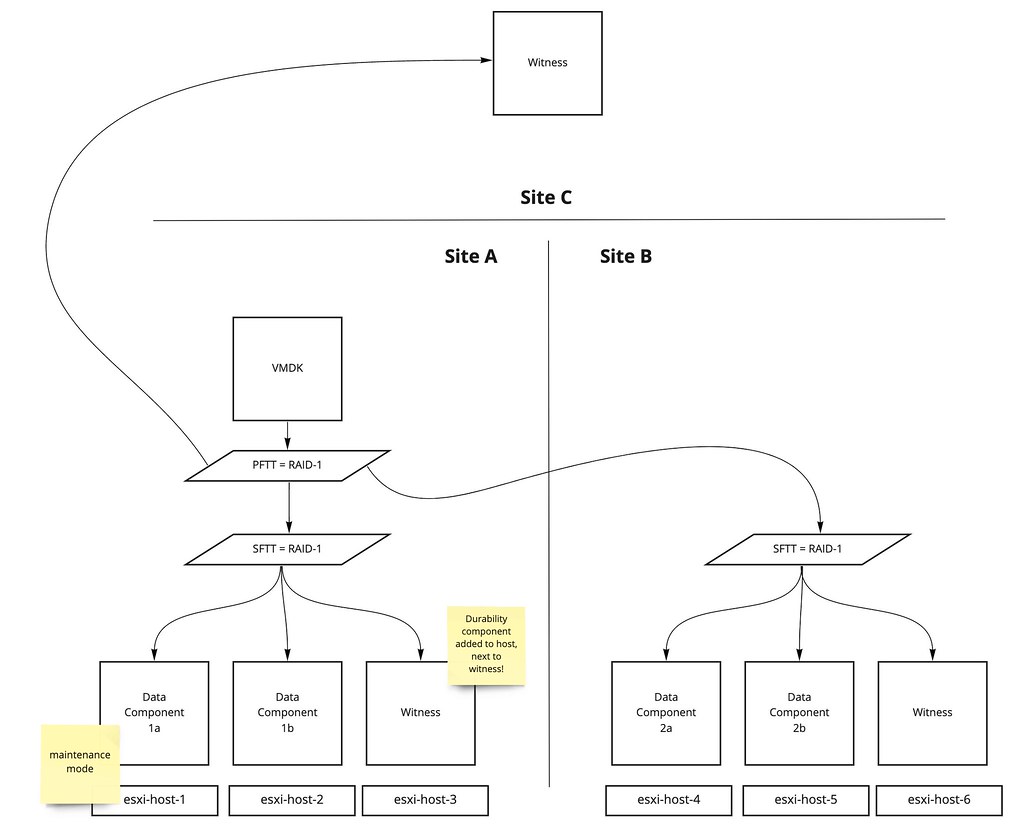
There was an interesting question on the VMware VMTN Community this week, although I wrote about this in 2016 I figured I would do a short write-up again as the procedure changed since 7.0u1. The question was if it was possible to make a particular host in a cluster the vSphere HA primary (or master as it was called previously) host. The use case was pretty straightforward, in this case, the customer had a stretched cluster configuration with vSAN, they wanted to make sure that the vSphere HA primary host was located in the “preferred” site, as this could potentially speed up the restart of VMs. Now, mind you, that when I say “speed up” we are talking about 2-3 seconds difference at most, but for some folks, this may be crucial. I personally would not recommend making configuration changes, but if you do want to do this, vSphere does have the option to do so.
When it comes to vSphere HA, there’s no UI option or anything like that to assign the “primary/master” host role. However, there’s the option to specify an advanced setting on a host level to indicate that a certain host needs to be favored during the primary/master election. Again, this is not very common for customers to configure, but if you desire to do so, it is possible. The advanced setting is called “fdm.nodeGoodness” and depending on which version you use, you will need to configure it either via the fdm.cfg file, or via the configstorecli. You can read about this process in-depth here.
Of course, I did try if this worked in my lab, here’s what I did, I first list the current configured advanced options using configstorecli for vSphere HA:
configstorecli config current get -g cluster -c ha -k fdm
{
"mem_reservation_MB": 200,
"memory_checker_time_in_secs": 0
}
Next, I will set the “node_goodness” for my host, when setting this it will need to be a positive value, in my case I am setting it to 10000000. I first dumped the current config in a json file:
configstorecli config current get -g cluster -c ha -k fdm > test.json
Next, I edited the file and added the setting “node_goodness” with a value of 10000000, so that is looks as follows:
{
"mem_reservation_MB": 200,
"memory_checker_time_in_secs": 0,
"node_goodness": 10000000
}
I then imported the file:
configstorecli config current set -g cluster -c ha -k fdm -infile test.json
After importing the file and reconfiguring for HA on one of my hosts, you can see in the screenshots below that the master role moved from 1507 to 1505.


I also created a quick demo, for those who prefer video content: