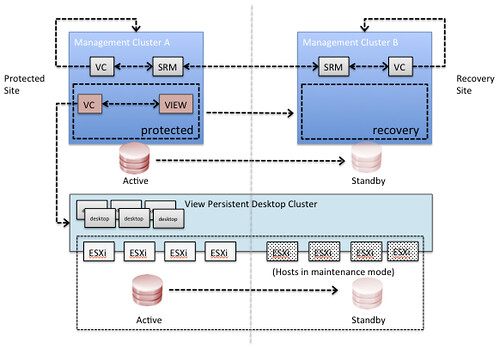
My colleague Ken Werneburg, also known as “@vmKen“, just published a new white paper. (Follow him if you aren’t yet!) This white paper talks about both SRM and Stretched Cluster solutions and explains the advantages and disadvantages of either. It provides a great overview in my opinion on when a stretched cluster should be implemented or when SRM makes more sense. Various goals and concepts are discussed and I think this is a must read for everyone exploring implementing a Stretched Clusters or SRM.
http://www.vmware.com/resources/techresources/10262
This paper is intended to clarify concepts involved with choosing solutions for vSphere site availability, and to help understand the use cases for availability solutions for the virtualized infrastructure. Specific guidance is given around the intended use of DR solutions like VMware vCenter Site Recovery Manager and contrasted with the intended use of geographically stretched clusters spanning multiple datacenters. While both solutions excel at their primary use case, their strengths lie in different areas which are explored within.