I know some of you have been waiting for this so I wanted to share some early results. I was in the UK last week and we managed to get an environment configured using persistent linked clone virtual desktops with View. We also managed to fail-over and fail-back desktops between two datacenters. The concepts is really similar to the vCloud Director DR concept.
In this scenario Site Recover Manager will be leveraged to fail-over all View management components. In each of the sites it is required to have a management vCenter Server and an SRM Server which aligns with standard SRM design concepts. Since it is difficult to use SRM for View persistent desktops there is no requirement to have an SRM environment connecting to the View desktop cluster’s vCenter Server. In order to facilitate a fail-over of the View desktops a simple mount of the volume is done. This could be using ‘esxcfg-volume -m’ for VMFS or using a DNS c-name mounting the NFS share after point the alias to the secondary NAS server.
What would the architecture look like? This is an oversimplified architecture, of course … but I just want to get the message across:
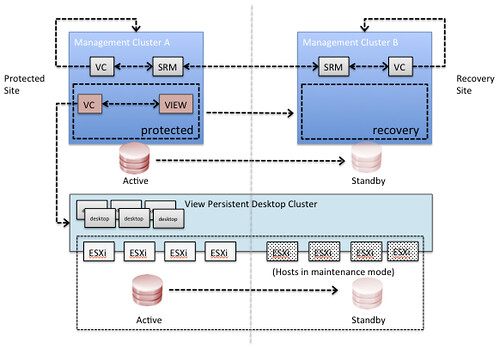
What would the steps be?
- Fail-over View management environment using SRM
- Validate all View management virtual machines are powered on
- Using your storage management utility break replication for the datastores connected to the View Desktop Cluster and make the datastores read/write (if required by storage platform)
- Mask the datastores to the recovery site (if required by storage platform)
- Using ESXi command line tools mount the volumes of the View Desktop Cluster cluster on each host of the cluster
- esxcfg-volume –m <;volume ID>;
or - point the DNS CNAME to the secondary NAS server and mount the NAS datastores
- Validate all volumes are available and visible in vCenter, if not rescan/refresh the storage
- Take the hosts out of maintenance mode for the View Desktop Cluster (or add the hosts to your cluster, depending on the chosen strategy)
- In our tests the virtual desktops were automatically powered on by vSphere HA. vSphere HA is aware of the situation before the fail-over and will power-on the virtual machines according to the last known state
These steps have been validated this week and we managed to successfully fail-over our desktops and fail them back. Keep in mind that we only did these tests two or three times, so don’t consider this article to be support statement. We used persistent linked clones as that was the request we had at that point, but we are certain this will work for the various different scenarios. We will extend our testings to include various other scenarios.
Cool right!?
In step 5 you still have a reference to vCloud director cluster, should say View resource cluster.
Good to see people talking about this subject more.
Duncan, thanks for that. There are many organizations out there waiting for this.
Should we assume that some sort of network virtualization technology such as OTV or VXLAN must be implemented? If not, have you successfully managed to automated the IP re-addressing for the entire View environment?
Have you looked into VPLEX as an alternative?
Does the solution require vCD? This may make sense for ISPs with multi-tenant solutions. What would be the options for standard View implementations?
Good job!
Thanks
Andre
What we tested was using a stretched L2 indeed Andre. Vplex could be an alternative, but there would be significant cost associated on top of regular replication.
I try and steer clients towards non-persistent desktops that utilize persona management to achieve a persistent experience. It makes DR a breeze since I’m only worried about replicating user data, persona data and application data (i.e. Thinapp packages). I have a View cluster with a pool (or pools_ of non-persistent desktops at the DR site already.
A failover occurs, update DNS (or if you’re lucky have a global traffic management solution like F5 GTM automate the DNS changes) and clients will now connect to the new pool(s) and their persona settings just follow them.
Yes, it is a demanding topic – thanks Duncan. With such a significant cost associated with this scenario it would seem replicating persona and user-data to secondary active View cluster would be cheaper, less complex and supportable?
Like I said Mark we will be exploring various different scenarios. This one was tested first due to customer requirements. I know multiple customers interested in this as their desktops are mission critical and unfortunately their apps are not flexible enough to build smart thin solutions as you suggest.
All good points and comments.
When you replicate with SRM to the DR side did your test validate replication between the brokers?
Thanks for all the leg work so far Duncan
I agree with Firbsy. We’re using Microsoft DFS replication to keep two user persona file servers in sync across rep sites. Simply light up a second view instance and name your pools the same and your done. Works amazingly well and you have a great way to show other c levels that VDI will not affect DR. It’s also fun to watch them say wow! When you connect to another site from their iPad and have their stuff follow them.
…test case we did this for hard firm requirement for persistent desktops due to a very specific custom application requirement. If it wasn’t for that non persistent and “mobile” persona’s would definitely be simpler. Sadly we have to find another way 🙂
Duncan, the vCD management cluster use case with PSO has GSS support as I understand it. Have GSS agreed to support the View use case and if so, is the View team working on supporting collateral (whitepaper, etc)?
Pete
Yes a white paper will be out soon Pete.
Hi Duncan, is the white paper available yet? Cheers, Guy
No it is not unfortunately…. it is being validated by VMware support as far as I know.
Hi there Duncan,
Great post with lots of valuable information.
Any news about the whitepaper that details this?
Hi Duncan,
I had somewhat similar successful story with persistent linked clones being migrated/replicated from one storage to another (using forced LUN mount w/o resignaturing).
Now that the old primary storage is replaced by the new one, we need to extend linked clones datastore.
At the storage level, LUN was successfully extended, but as it is (correctly) recognized as a snapshot LUN, it will not allow extents in ESXi (v4).
Any ideas of how to extend such datastore – is it possible at all (e.g., to “convert” a snapshot to a “normal” LUN w/o resignaturing it)?
Alternatively, I could simply add another datastore for linked clones, if it is impossible to extend the current one.
Thank you in advance,
Kind regards,
prezha
hello!
take a look to this solution, it covers both, linked clones and also full desktop failover:
http://www.youtube.com/watch?v=I1D8PnwF12A
regards,
kaido