Last week there was a question on VMTN around maintenance mode, this customer wanted to find out which vSAN Maintenance Mode option was used while the host was placed in maintenance mode. The person who placed the host into maintenance wasn’t around, and I guess the customer wanted to know if data was moved from the host or not. They looked at the events and tasks, but unfortunately it wasn’t obvious from that vCenter section, next up were the logs. I also looked at the logs, and you would expect this info to be stored in hostd.log, but it wasn’t, so where is it? Well it actually is a configuration item, and you can dig it up here:
Pre ESXi 7.0 the info is stored in the “esx.conf” file, just grep for “hostDecommission”. Let me show you:
$ grep "/vsan/hostDecommission" /etc/vmware/esx.conf /vsan/hostDecommissionVersion = "10" /vsan/hostDecommissionState = "decom-state-decommissioned" /vsan/hostDecommissionMode = "decom-mode-ensure-object-accessibility"
If the ESX is at 7.0 or later, just run the below config store command:
$ configstorecli config current get -c vsan -g system -k host_state
{
"decom_mode": "ENSUREOBJECT_ACCESSIBILITY",
"decom_state": "DECOMMISSIONED",
"decom_version": 0
}
I hope that helps others who have a similar question!
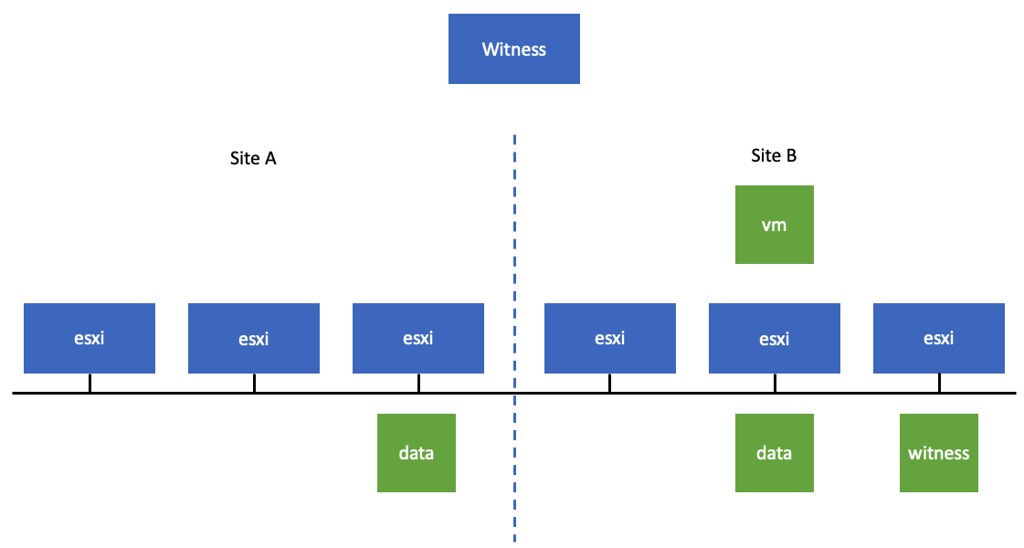
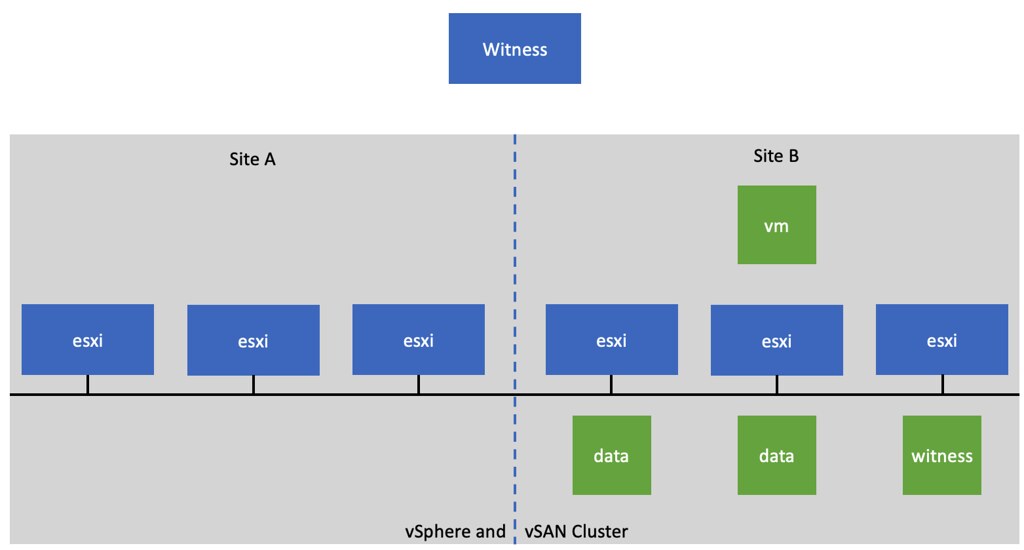
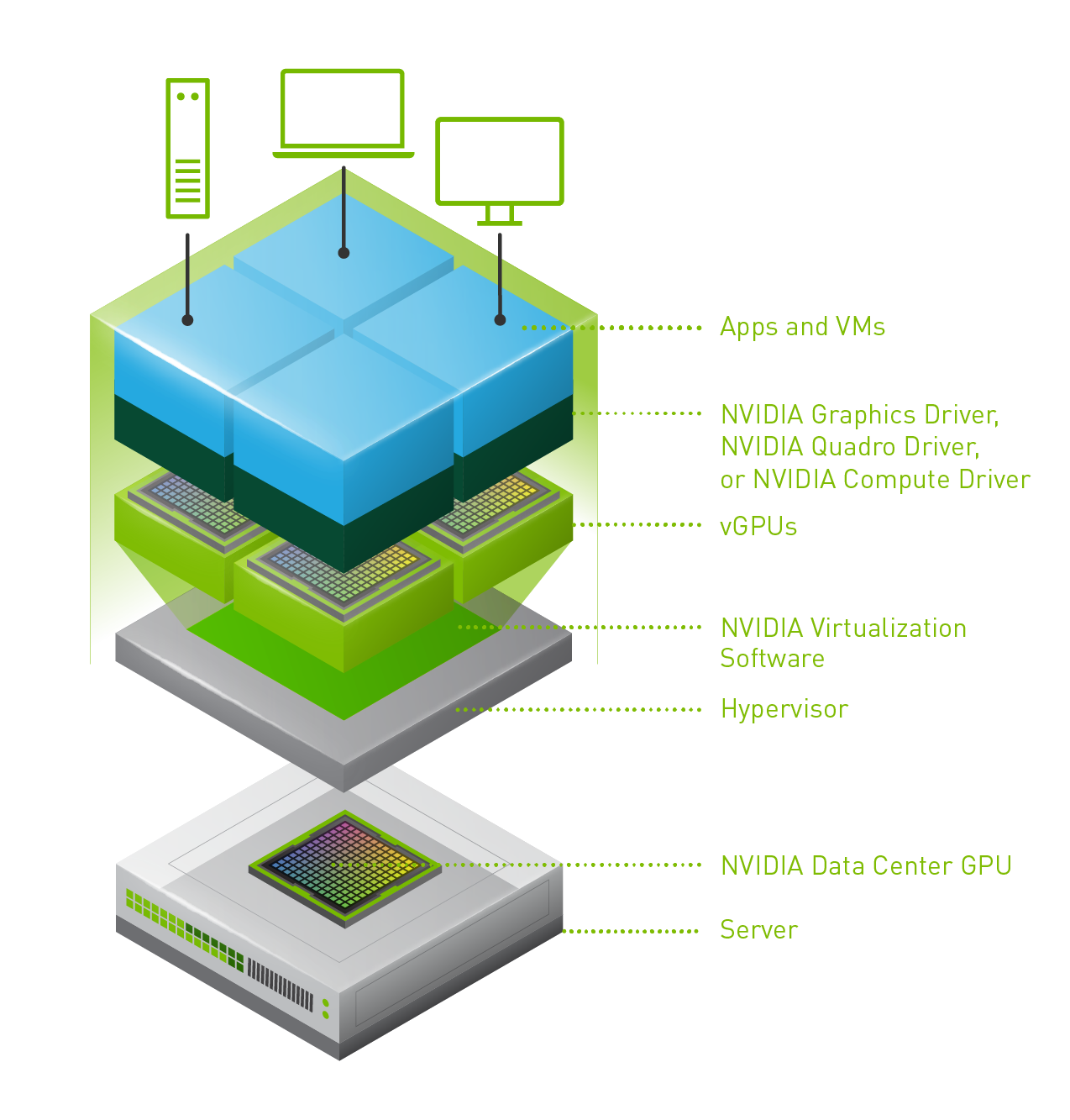 Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in
Last week one of our engineers shared something which I found very interesting. I have been playing with Virtual Reality technology and NVIDIA vGPUs for 2 months now. One thing I noticed is that we (VMware) introduced support for vMotion in vSphere 6.7 and support for vMotion of multi vGPU VMs in vSphere 6.7 U3. In order to enable this, you need to set an advanced setting first. William Lam described this in