I was going through the list of sessions when I spotted a session Persistent Memory by Rich Brunner and Rajesh V. Quickly after that I noticed that there also was a PMEM session by the perf team available. Both CTO2860BU and VIN2183BU I would highly recommend watching. I would recommend starting with CTO2860BU though, is it gives a great introduction to what PMEM brings to the table. I scribbled down some notes, and they may appear somewhat random, considering I am covering 2 sessions in 1 article, but hopefully the main idea is clear.
I think the sub-title of the sessions make clear what PMEM is about: Storage at Memory Speed. This is what Richard talks about in CTO2860BU during the introduction. I thought this slide explained the difference pretty well, it is all about the access times:
- 10,000,000 ns – HDD
- 100,000 ns – SAS SSD
- 10,000 ns – NVMe
- 50-300 ns – PMEM
- 30-100ns – DRAM
So that is 10 million nanoseconds vs 50 to 300 nanoseconds. Just to give you an idea, that is roughly the speed difference between the space shuttle and a starfish. But that isn’t the only major benefit of persistent memory. Another huge advantage is that PMEM devices, depending on how they are used, are byte addressable. Compare this to 512KB, 8KB / 4KB reads many storage systems require. When you have to change a byte, you no longer incur that overhead.
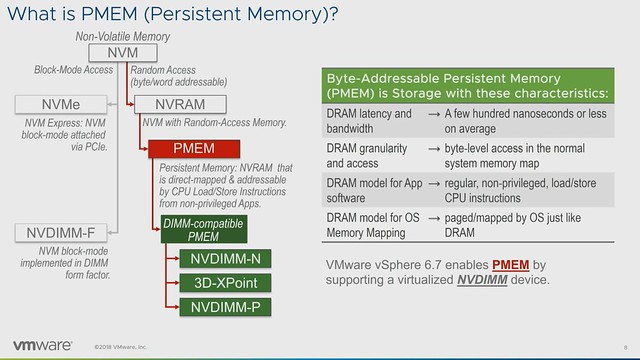
As of vSphere 6.7, we have PMEM support. A PMEM can be accessed as a block device or as a disk, but the other option would be to access it as “PMEM”. Meaning that in the latter case we serve a virtual PMEM device to the VM and the Guest OS sees this as PMEM. What also was briefly discussed in Richard’s talk was the different types of PMEM. In general, there are 4 different types, but most commonly talked about are 2. These two are NVDIMM-N and Intel Optane. With the difference being that NVDIMM-N has DRAM memory backed by NAND, and where persistence is achieved by writing to NAND only during shutdown / power-fail. Whereas with Intel Optane there’s what Intel calls 3D XPoint Memory on the DIMM directly addressable. The other two mentioned were “DRAM backed to NVMe” and NVDIMM-P, where the first was an effort by HPe which has been discontinued and NVDIMM-P seems to be under development and is expected in 2019 roughly.
When discussing the vSphere features that support PMEM what I found most interesting was the fact that DRS is fully aware of VMs using PMEM during load balancing. It will take this in to account, and as the cost is higher for a migration of a PMEM enabled VM it will most likely select a VM backed by shared storage. Of course, when doing maintenance DRS will move the VMs with PMEM to a host which has sufficient capacity. Also, FT is fully supported.
In the second session,VIN2183BU, Praveen and Qasim discussed performance details. After a short introduction, they dive deep into performance and how you can take advantage of the technology. First they discuss the different modes in which persistent memory can be exposed to the VM/Guest OS, I am listing these out as they are useful to know.
- vPMEMDisk = exposed to guest as a regular SCSI/NVMe device, VMDKs are stored on PMEM Datastore
- vPMEM = Exposes the NVDIMM device in a “passthrough manner, guest can use it as block device or byte addressable direct access device (DAX), this is the fastest mode and most modern OS’s support this
- vPMEM-aware = This is similar to the mode above, but the difference is that the application understands how to take advantage of vPMEM

Next they discussed the various performance tests and comparisons they have done. What they have tested is various modes and compare that as well to the performance of NVMe SSD. What stood out most to me is that both the vPMEM and vPMEM-Aware mode provide great performance, up to an 8x performance increase. In the case of vPMEMDisk that is different, and that has to do with the overhead there is. Because it is presented as a block device there’s significant IO amplification which in the case of “4KB random writes” even leads to a throughput that is lower for NVMDIMM than it is for NVMe. During the session it is mentioned that both VMware as well as Intel are looking to optimize their part of the solution to solve this issue. What was most impressive though wasn’t the throughput but the latency, there was a 225x improvement measured between NVMe and vPMEM and vPMEM-Aware. Although vPMEMDisk was higher than vPMEM and vPMEM-aware, it was still significantly lower than NVMe and very consistent across reads and writes.
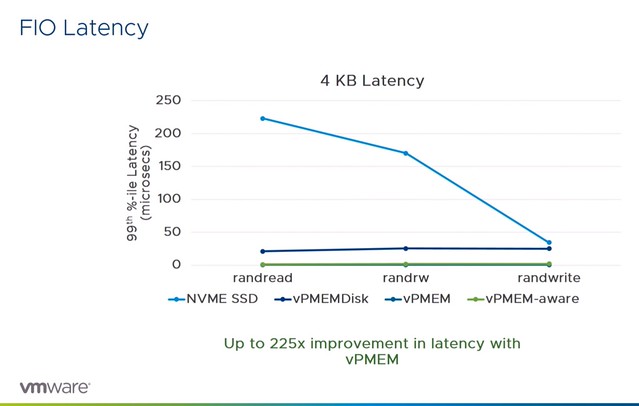
This was just the FIO example, this is followed by examples for various applications both scale out and scale up solutions. What I found interesting were the Redis tests, nice performance gains at a much lower latency, but more importantly, the cost will probably go down when leveraging persistent memory instead of pure DRAM.
Last but not least tests were conducted around performance during vMotion and the peformance of the vMotion process itself. In both cases using vPMEM or vPMEM-aware can be very beneficial for the application and the vMotion process.
Both great sessions, again highly recommended watching both.