This question was asked on the VMTN community forum and it is a very valid question. Our documentation explains this scenario, but only to a certain level and it seems to be causing some confusion as we speak. To be honest, it is fairly complex to understand. Internally we had a discussion with engineering about it and it took us a while to grasp it. As the documentation explains, the failure scenarios are all about maintaining quorum. If quorum is lost, the data will become inaccessible. This makes perfect sense, as vSAN will always aim to protect the consistency and reliability of data first.
So how does this work, well when creating a policy for a stretched cluster you specify Primary Failures To Tolerate (PFTT) and Secondary Failures To Tolerate (SFTT). PFTT can be seen as “site failures”, and you can always only tolerate 1 at most. SFTT can be seen as host failures, and you can define this between 0 and 3. Where we by far see FTT=1 (RAID-1 or RAID-5) and FTT=2 (RAID-6) the most. Now, if you have 1 full site failure, then on top of that you can tolerate SFTT host failures. So if you have SFTT=1 then this means that 2 host failures in the site that survived would result in data becoming inaccessible.
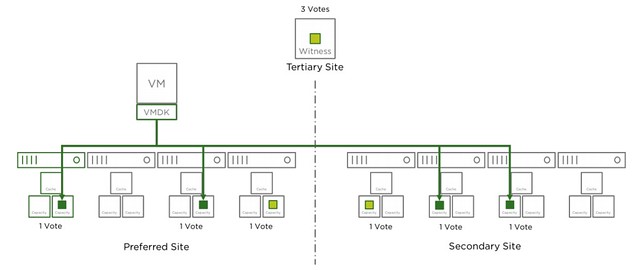
Where this gets tricky is when the Witness fails, why? Well because the witness is seen as a site failure. This means that if you have lets say 2 hosts failing in Data Site A and 1 host failing in Data Site B, while you had SFTT=2 assigned to your components, that your objects that are impacted will become inaccessible. Simply because you exceeded PFTT and SFTT. I hope that makes sense? Lets show that in a diagram (borrowed it from our documentation) for different failures, I suggest you do a “vote count” so that it is obvious why this happens. The total vote count is 9. Which means that the object will be accessible as long as the remaining vote count is 5 or higher.
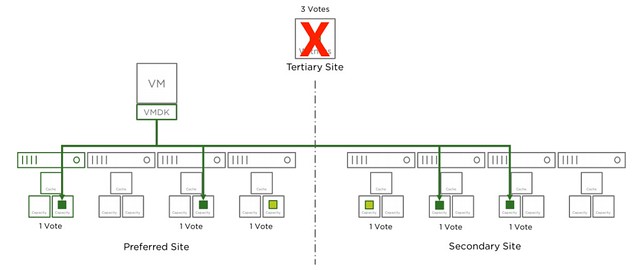
Now that the witness has failed, as shown in the next diagram, we lose 3 votes of the total 9 votes, no problem as we need 5 to remain access to the data.
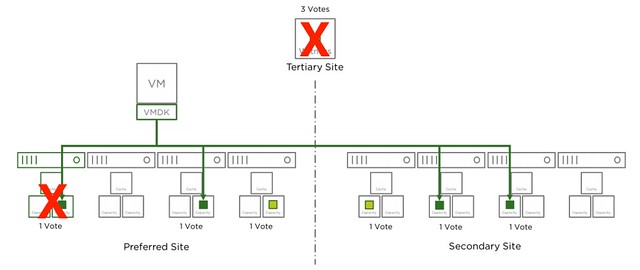
In the next diagram another host has failed in the environment, we now lost 4 votes out of the 9. Which means we still have 5 out of 9 and as such remain access.
And there we go, in the next diagram we just lost another one host, in this case it is the same location as the first host, but this could also be a host in the secondary site. Either way, this means we only have 4 votes left out of the 9. We needed 5 at a minimum, which means we now lose access to the data for those objects impacted. As stated earlier, vSAN does this to avoid any type of corruption/conflicts.
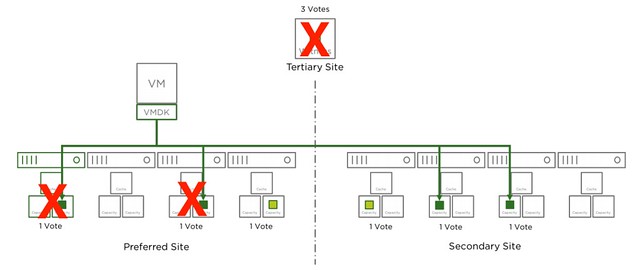
The same applies to RAID-6 of course. With RAID-6 as stated you can tolerate 1 full site failure and 2 host failures on top of that, but if the witness fails this means you can only lose 1 host in each of the sites before data may become inaccessible. I hope this helps those people running through failure scenarios.
Why witness has 3 votes?
as stated in the stretched clustering doc:
In short, each component has a vote, and a quorum of votes must be
present for an object to be accessible. Each site will have an equal number of votes and there will be
an even distribution of votes within a site.
Ok, make sense, Thanks!
Duncan, why is Vsan Essentials 2d edition no longer available on Safari? Where can I buy a hard copy?
A more vsan related question, because of GDPR I need to enable encryption on my vsan, easy enough with KMS, but I`m also using Vsphere replication, is there any settings that i need to be aware of, does the second Vcenter need to have access to the same KMS server?
How is the replicated encrypted data ,decrypted on the Second Vcenter ?
you can download it for free here: vsan-essentials.com or read it online there as well.
when it comes to vsphere replication, the IO is actually replicated before it is encrypted, so it travels to the remote location in a normal state.
Thank you so much for the reply Ducan, real life saver! Thanks for the book link , it was ,and is a great resource for my VSAN implementation.
Hello,
Would you kindly write a post about votes in stretched cluster ?
I’m a bit confused about some points. I read on Cormac Hogan’s site that in the case of RAID-5, one component will have 2 votes, because vSAN wants odd number of votes. And in the case of stretched cluster with PFFT=1 and SFFT=1/Raid5, all the components on secondary site have 1 vote.
So, prefered site will have 5 votes, secondary 4 votes.
Here, you state that
“Each site will have an equal number of votes and there will be
an even distribution of votes within a site.”
I’m a bit lost on all this.
Let’s say we take a stretched cluster 4+4+1, VM PFFT=1 SFFT=1 method=R5
For a single object (say, one <255GB vmdk) :
The preferred site will have 4 components, thus 4 votes.
The secondary site will have 4 components, thus 4 votes.
The witness site will have … 4 votes ?
So in this exemple, if I loose the witness, I'm left with 8 votes out of a 7 required majority. So it's good.
If I loose 1 node on secondary site, I'm left with 7 votes, I'm ok.
If I loose 1 more node on secondary site, I have 6 votes, the object become inaccessible, even if I have localy the 3 data + 1 parity on my 4 local nodes, right ?
This is not so trivial 🙁
Thanks for help
Also, if you take again my example of 4+4+1, PFFT=1 SFFT=1
If I loose the witness plus 1 ESXi on each site, since I have SFFT=1 I have lost no site (appart the witness) but I have only 6 votes for quorum, so I loose everything, right ?
The witness is considered to be a site. So you have lost a full site in the above scenario.
Your example is correct indeed… If I have time I will try to write something up. Not sure when that will be.
Are you sure about that ? Seems very strange to me.
I always saw a site as a “failure domain” rather than a number of votes. If I take tntteam scenario, we actually have 3 fault domains : Site-A, Site-B and the witness host.
Let’s give all those 3 fault domains a token, evenly distributed as stated.
To be able to achieve quorum, I obviously need 2 token out of 3.
So, if I loose my Witness host, I loose 1 token. Only 2 left.
Next, I loose a host in Site-A.
Site-A and Site-B are still able to communicate and achieve quorum given the fact they both have a token.
In this situation, I don’t see how the fact I lost a host in Site-A is an issue ?
In Duncan’s example, in this case, I guess that the “vote” that was holded by the host we lost goes to the 4th host that’s still online and rebuild from Site-B can begin.
For me, the issue in your explanation is that you are not taking into account the fact that a vote can be redistributed to another host within the same failure domain.
Or at least this is what I think and what, for me, makes the most sense
After thinking about it last night…
Mea culpa, I didn’t read well : “plus 1 ESXi ON EACH SITE”. In that case, yes, you may loose data.
In your example, you have to see the cluster as 1 logical entity subdivided into 2 fault domains. On the side you have also your witness host which is considered to be the 3rd fault domain.
On top of that, we know that PFTT = 1 >> you can loose 1 fault domain out the 3 that are available. AND, SFTT= 1 >> you can loose 1 host amongst 8 total.
Next, it seems important to me to split 2 very different things :
– on the 1st side we have the split brain issue which is what we want to address introducing the quorum and the witness host.
– on the other side we have a possible data loss issue.
What is however unclear to me is, indeed, how the votes are exactly calculated.
It comes down to how votes are actually assigned and under what rule.
If, like I said in my previous post, you consider that each fault domain has only 1 vote, it makes things much more easy from a split brain point of view : as long as each site has at least one host that can talk with another host on the other side there is NO split brain but, of course a possible data loss.
also, just thinking about that but, in case of a streched cluster, is the SFTT not applicable to each data site ? I guess that would make sense since we are talking about a mirror. that would mean with a SFTT=1 we could actually loose 2 physical machines on each “data site”.
**Of course I mean loosing 1 physical machines on each “data site”
I understand that, that would be the case if the quorum mechanism was implemented hierarchical, but it is a single level implementation due to various factors. I have already requested the developers to look into this and if this behavior can be changed. I understand you are sceptical, here’s the official documentation describing the same problem, but with fewer words: https://storagehub.vmware.com/t/vmware-vsan/vsan-stretched-cluster-guide/multiple-simultaneous-failures-2/
Yes I am sure about that, I tested it, discussed it with the Product Manager, then verified with Engineering.
Ok it’s good to know, thank you 🙂
However : about the vote count.
If I resume what you are saying, it is the “final vote count” (after x failure) which is defining the fact vsan decides if we have, or not, access to the “impacted objects” (those residing on hosts from which we lost the votes).
Based on that, in your example, you have 4 host’s on each site and the witness host. The, you assume that there are 9 votes in total. Why 9 ? Why not 12 ?
Because, and that’s my point, from this number of votes and SFTT depends the availability of the data if I follow your reasoning.
For example, what if I have a cluster of 20 hosts and a witness ? Do I still have 9 votes total or how many exactly ? Because if I have 30 votes rather than 9 (same SFTT) is changes everything.
Then I need 16 votes to achieve quorum. If I loose my witness, I still can loose 4 hosts on any site while still achieving quorum.
Do you know exactly how the voting mechanism is organised ?
You see where I’m confused ? I don’t know if I am explaining clearly enough what I’m not understanding ?
There seems to be a mix between the concept of quorum to avoid split brain situation and the SFTT which is a local data protection feature. I thought that both are linked together, and that this SFTT is applicable to each site.
the number of hosts isn’t relevant even. We are actually talking about votes per object in total, and votes per component as such. if you have 30 hosts then with the above example you probably would still have the same number of votes, unless you have additional copies of the data, then the number of votes changes. Still the concept, when you have an additional number of copies, remains the same.
What I would suggest, if it is hard to follow: Set up a stretched cluster, deploy a VM, go to the command line (RVC) and look at the vote count for that VM. Then deploy another VM, but this time with for instance FTT=2 or a stripe, and then look at the vote count again. That probably is the easiest way.
What happens if you have a stretched setup with 3 nodes on both sites and one node faits on the secondary site? Pfff=1 & Sftt=0? And what if in this scenario the primaire site fails also then we have nothing left?
if you have PFTT=1 and SFTT=0 you have typically for each VMs 2 components. If your primary site fails, and now 1 node fails in the secondary site, then ALL virtual machines which had a component on that node that failed in the secondary site will lose access. Why? Well you specified in policy: 2 copies of the data, 1 in each location. That is the constraint / risk you agreed to / provided to the system.
Thanks for your comment.
I guess you mean when the witness appliance(site) is available.
[Quote]if you have PFTT=1 and SFTT=0 you have typically for each VMs 2 components. If your primary site fails, and now 1 node fails in the secondary site, then ALL virtual machines which had a component on that node that failed in the secondary site will lose access.[/Quote]
Hi Duncan, I have one more question to the PFTT=1, SFTT=0 scenario.
In case there is a disk failure on one of the sites, what will happen to the affected VMs? Will they access the data from the secondary site? Or will they be restarted on the secondary site?
If there are just (2) nodes at each site, will that be a supported configuration?
Hello Duncan, I am trying to understand if I understand the concept correctly. What happens with PFTT=1 and SFTT=0 and both the prefferred site and witness site become isolated? Will the virtual machines in the secondary site become unavailable due to quorum minority (<50%)?
In that case you lose access to the component due to quorum minority indeed.
Just bought the deepdive book to dig into this subject 😉 One last questions, what is your opinion on using PFTT=1 and SFTT=0 in a production environment?
Nothing wrong with it, unless as you understand that a full site failure and a single disk failure would lead to data loss, so I would do SFTT=0 for particular workloads and SFTT=1 or 2 for others, depending on their relative importance and the SLA.
Duncan, just to be sure, if I would use PFTT=1 and SFTT=1 and both the prefferred site and witness site become isolated, the virtual machines in the secondary site still become unavailable due to quorum minority. With two site failures (one of them being the witness) all objects become inaccessable regardless of the SFTT value, Right?
Correct
Hi Dunan, would this ever be an issue if following the ‘2n+1’ rule of thumb for the number of hosts per site? In the example of SFTT of 2, you would then need 5 hosts (5+5+1). Cheers.