vMotion is probably my favourite VMware feature ever. It is one of those features which revolutionized the world and just when you think they can’t really innovate anymore they take it to a whole new level. So what is new?
- Cross vSwitch vMotion
- Cross vCenter vMotion
- Long Distance vMotion
- vMotion Network improvements
- No requirement for L2 adjacency any longer!
- vMotion support for Microsoft Clusters using physical RDMs
That is a nice long list indeed. Lets discuss each of these new features one by one and lets start at the top with Cross vSwitch vMotion. Cross vSwitch vMotion basically allows you to do what the name tells you. It allows you to migrate virtual machines between different vSwitches. Not just from vSS to vSS but also from vSS to vDS and vDS to vDS. Note that vDS to vSS is not supported. This is because when migrating from vDS metadata of the VM is transferred as well and the vSwitch does not have this logic and cannot handle the metadata. Note that the IP Address of the VM that you are migrating will not magically change, so you will need to make sure both the source and the destination portgroup belong to the same layer 2 network. All of this is very useful during for instance Datacenter Migrations or when you are moving VMs between clusters for instance or are migrating to a new vCenter instance even.
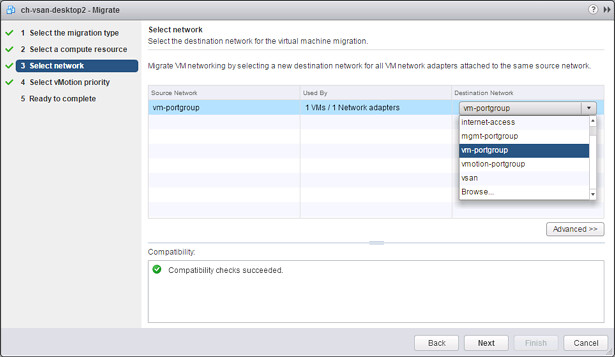
Next on the list is Cross vCenter vMotion. This is something that came up fairly frequent when talking about vMotion, will we ever have the ability to move a VM to a new vCenter Server instance? Well as of vSphere 6.0 this is indeed possible. Not only can you move between vCenter Servers but you can do this with all the different migration types there are: change compute / storage / network. You can even do it without having a shared datastore between the source and destination vCenter aka “shared nothing migration. This functionality will come in handy when you are migrating to a different vCenter instance or even when you are migrating workloads to a different location. Note, it is a requirement for the source and destination vCenter Server to belong to the same SSO domain. What I love about this feature is that when the VM is migrated things like alarms, events, HA and DRS settings are all migrated with it. So if you have affinity rules or changed the host isolation response or set a limit or reservation it will follow the VM!
My personal favourite is Long Distance vMotion. When I say long distance, I do mean long distance. Remember that the max tolerated latency was 10ms for vMotion? With this new feature that just went up to 150ms. Long distance vMotion uses socket buffer resizing techniques to ensure that migrations succeed when latency is high. Note that this will work with any storage system, both VMFS and NFS based solutions are fully supported. (** was announced with 100ms, but updated to 150ms! **)
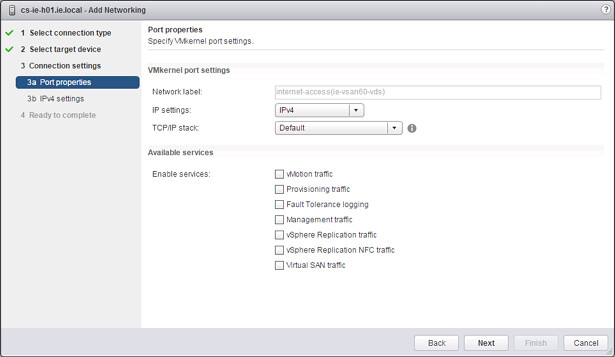
Then there are the network enhancements. First and foremost, vMotion traffic is now fully supported over an L3 connection. So no longer is there the need for L2 adjacency for your vMotion network, I know a lot of you have asked for this and I am happy to be able to announce it. On top of that. You can now also specify which VMkernel interface should be used for migration of cold data. It is not something many people are aware off, but depending on the type of migration you are doing and the type of VM you are migrating it could be in previous versions that the Management Network was used to transfer data. (Frank Denneman described this scenario in this post.) For this specific scenario it is now possible to define a VMkernel interface for “Provisioning traffic” as shown in the screenshot below. This interface will be used for, and let me quote the documentation here, “Supports the traffic for virtual machine cold migration, cloning, and snapshot creation. You can use the provisioning TPC/IP stack to handle NFC (network file copy) traffic during long-distance vMotion. NFC provides a file-type aware FTP service for vSphere, ESXi uses NFC for copying and moving data between datastores.”
Full support for vMotion of Microsoft Cluster virtual machines is also newly introduced in vSphere 6.0. Note that these VMs will need to use physical RDMs and only supported with Windows 2008, 2008 R2, 2012 and 2012 R2. Very useful if you ask me when you need to do maintenance or you have resource contention of some kind.
That was it for now… There is some more stuff coming with regards to vMotion but I cannot disclose that yet unfortunately.
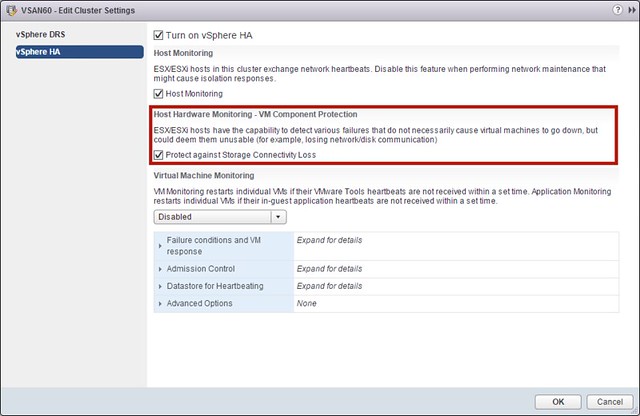
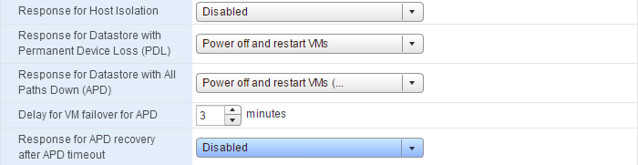
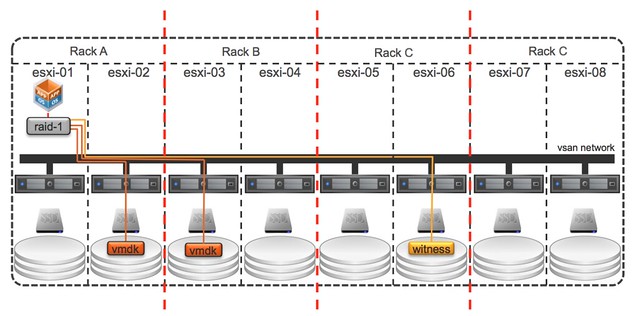
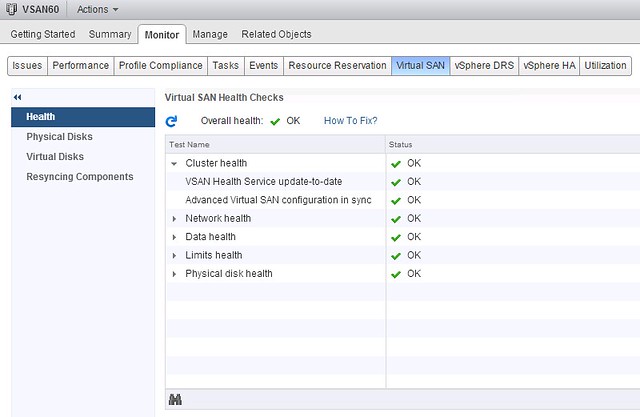
 That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.
That is a nice long list indeed. Let my discuss some of these features a bit more in-depth. First of all “all-flash” configurations as that is a request that I have had many many times. In this new version of VSAN you can point out which devices should be used for caching and which will serve as a capacity tier. This means that you can use your enterprise grade flash device as a write cache (still a requirement) and then use your regular MLC devices as the capacity tier. Note that of course the devices will need to be on the HCL and that they will need to be capable of supporting 0.2 TBW per day (TB written) over a period of 5 years. For a drive that needs to be able to sustain 0.2 TBW per day, this means that over 5 years it needs to be capable of 365TB of writes. So far tests have shown that you should be able to hit ~90K IOPS per host, that is some serious horsepower in a big cluster indeed.