Instead of one generic post with a bunch of data I picked a couple of features and dug a little bit deeper, today I will be discussing what is new for HA in vSphere 6.0. Lets start with a list and then look at the features / enhancements individually:
- Support for Virtual Volumes – With Virtual Volumes a new type of storage entity is introduced in vSphere 6.0.
- VM Component Protection – This allows HA to respond to a scenario where the connection to the virtual machine’s datastore is impacted temporarily or permanently.
- “Response for Datastore with All Paths Down”
- “Response for Datastore with Permanent Device Loss”
- Increased scale – Cluster limit has grown from 32 to 64 hosts and to a max of 8000 VMs per cluster
- Registration of “HA Disabled” VMs on hosts after failure
Lets start with support for Virtual Volumes. It may sound like this is a given but as the whole concept of a VMFS volume no longer exists with Virtual Volumes and VMs have “virtual volumes” instead of VMDKs you can imagine that some work was needed to allow for HA to restart virtual machines stored on a VVOL enabled storage system.
VM Component Protection (VMCP) is in my opinion THE big thing that got added to vSphere HA. What this feature basically allows you to do is protect yourself against storage failures. There are two types of failures VMCP will respond to and those are PDL and APD. Before we look at some of the details, I want to point out that configuring is extremely simple… Just one tickbox to enable it.
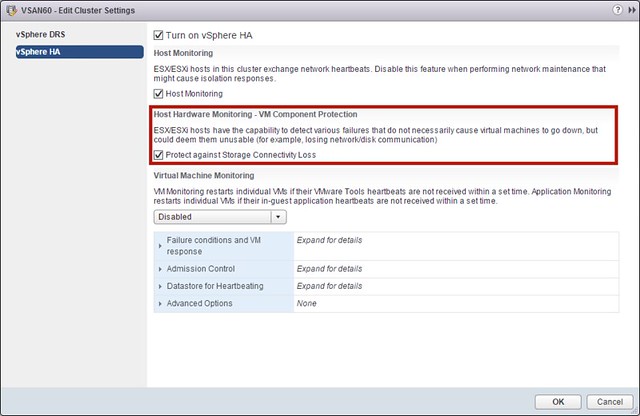
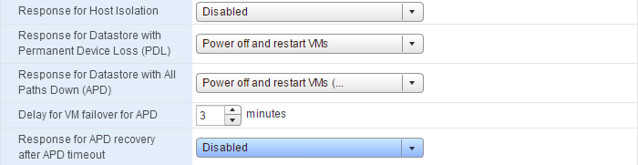
In the case of a PDL (permanent device loss), this is something HA already was capable of doing when configured through the command line, a VM will be restarted instantly when a PDL signal is issued by the storage system. For an APD (all paths down) this is a bit different. A PDL more or less indicates that the storage device does not expect the device to return any time soon. An APD is more of an unknown situation, it may return… it may not… and no clue how long it takes. With vSphere 5.1 some changes were introduced to the way APD is handled by the hypervisor in this mechanism is leveraged by HA to allow for a response. (Cormac wrote an excellent post about this APD handling here.) When an APD occurs a timer starts. After 140 seconds the APD is declared and the device is marked as APD time out. When the 140 seconds has passed HA will start counting. The HA time out is 3 minutes. When the 3 minutes has passed HA can restart the virtual machine, but you can configure VMCP to respond differently if you want it to. You could for instance specify that events are issued that a PDL or APD has occurred. You can also specify how aggressively HA needs to try to restart VMs that are impacted by an APD. Note that aggressive / conservative refers to the likelihood of HA being able to restart VMs. When set to “conservative” HA will only restart the VM that is impacted by the APD if it knows another host can restart it. In the case of “aggressive” HA will try to restart the VM even if it doesn’t know the state of the other hosts, which could lead to a situation where your VM is not restarted as there is no host that has access to the datastore the VM is located on. It is also good to know that if the APD is lifted and access to the storage is restored during the total of roughly 5 minutes and 20 seconds it would take to reboot the VM, that HA will not do anything unless you explicitly configure it do so. This is where the “Response for APD recovery after APD timeout” comes in to play.
Increased scale is pretty straight forward, from 32 to 64 hosts and a total of 8000 VMs per cluster. I don’t know too many customers hitting this boundaries but I do come across a request like this occasionally. So if you want to grow your cluster, you can now do so. Do note that you may hit other limits like the LUN limit or the VM limit or…
Registration of HA Disabled VMs after a failure is a feature I have requested a long time ago. I am glad to see this made it in to the release. Basically when you have HA disabled on a specific VM this feature will make sure that the VM gets registered on another host after a failure. This will allow you to easily power-on that VM when needed without needed to manually re-register it yourself. Note, HA will not do a power-on of the VM but it will just register it for you.
That was it for now…
Is the “Registration of HA Disabled VMs after a failure” functionality now a default behavior? I could see scenarios where this behavior is not wanted (Nutanix controller VMs, for example).
Sure you can disable it by using an advanced setting called “das.reregisterRestartDisabledVMs”. Set it to “true” or “false”
Any plans for VMCP against network failures similar to competitor vizors?
A VM might not be impacted by the loss of disk connectivity but network disruption will cause an immediate outage.
Yes this is something that is part of the roadmap, I cannot comment on when this will be released however.
Does VMCP repond to RDM /VMDK failures?
No, it responds to PDL / APD scenarios.
My understanding is that this functionality offers a consistent recovery behaviour (for HA-disabled VMs) where VMs are rapidly re-registered, and therefore made available within the cluster in a powered-off state.
HA-enabled default behaviour may be considered undesirable (e.g. you might not want it to automatically restart a VM/VMs if it was powered-on at the point of failure). Instead, you might want the VM to be made available, but powered-off. (Just as an example, you may have strict inter-VM dependencies that need to be respected, or you may need VM:VM affinity rules to be adhered to).
In previous versions of vSphere, disabling HA for a VM was problematic, and led to “RTO exposure” because of the following :
If a VM had HA disabled, and its host failed:
If that VM was powered-off at the point of host failure, after a small period of time it became orphaned. It was then possible to recover the VM by re-registering it to another host.
But, in the case that the VM was powered-on at the point of failure, it became “disconnected” in VCenter. It was not possible to re-register the VM in this state, so it was effectively stranded, and inoperable on the host, until the host was recovered (which (depending on failure mode) would require start, or even rebuild).
Exactly Mr Wodge… 🙂
Hi Duncan,
Love the new APD failure handling! A missing piece of the HA story!
Thank you!
Gary
If there is a Datastore A which is presented on Host A & B; VM1 which is registered on Host A; if the datastore A fails completely it will also not be available on ESXi Host B. Then will the VM 1 restart? What would happen in this scenario?
thanks in advance
If the datastore is not connected to either of the hosts then the VM cannot be restarted.
Hi Duncan
How can HA failover a VM when there is a PDL. Wont PDL affect all the hosts?
Depends on the type of PDL I guess… Some types could partially impact a cluster, others could be cluster wide.
Hi Duncan
Thank you for the reply. I was under the impression that a PDL would occur when there is a lung deletion or some kind of corruption. In that case, how will only affect partial cluster? Do you know of examples of partial PDL?
Imran
Hi Imran,
Check below link — hope this answers your concern
http://featurewalkthrough.vmware.com/#!/vsphere-6-0/vsphere-high-availability
Well you can remove a host from a storage group right, that way only 1 host is impacted….
Imran,
I had the same reaction, if the device is down, what good could it be to change hosts? Since the device down comes from the storage, it only makes sense if the storage would respond differently to different hosts, i.e., if this PDL is the consequence of a storage policy. (Fat fingers ? 🙂
Hi Duncan
For VMCP feature, does the “Master” host that restarting the VMs with APD/PDL problem?
If yes, how does the “Master” host know that? and If not, who does restarting the VMs?
Thanks
When having a lost storage access on an ESXi host, the VM will restart on a different host that has access to its related datastore in this case if we have the VMCP enabled?
Hi Duncan, what happens if the array goes down? In that case all the hosts are on APD.
If VMP APD response is power off and restart VMs would the VM be powered off?
We are looking for that behavior as some linux VMs keep responding to ping even when the array is down and that could be cause some issues.
Is there any way to have VMs powered off on an APD event?
Thanks in advance!