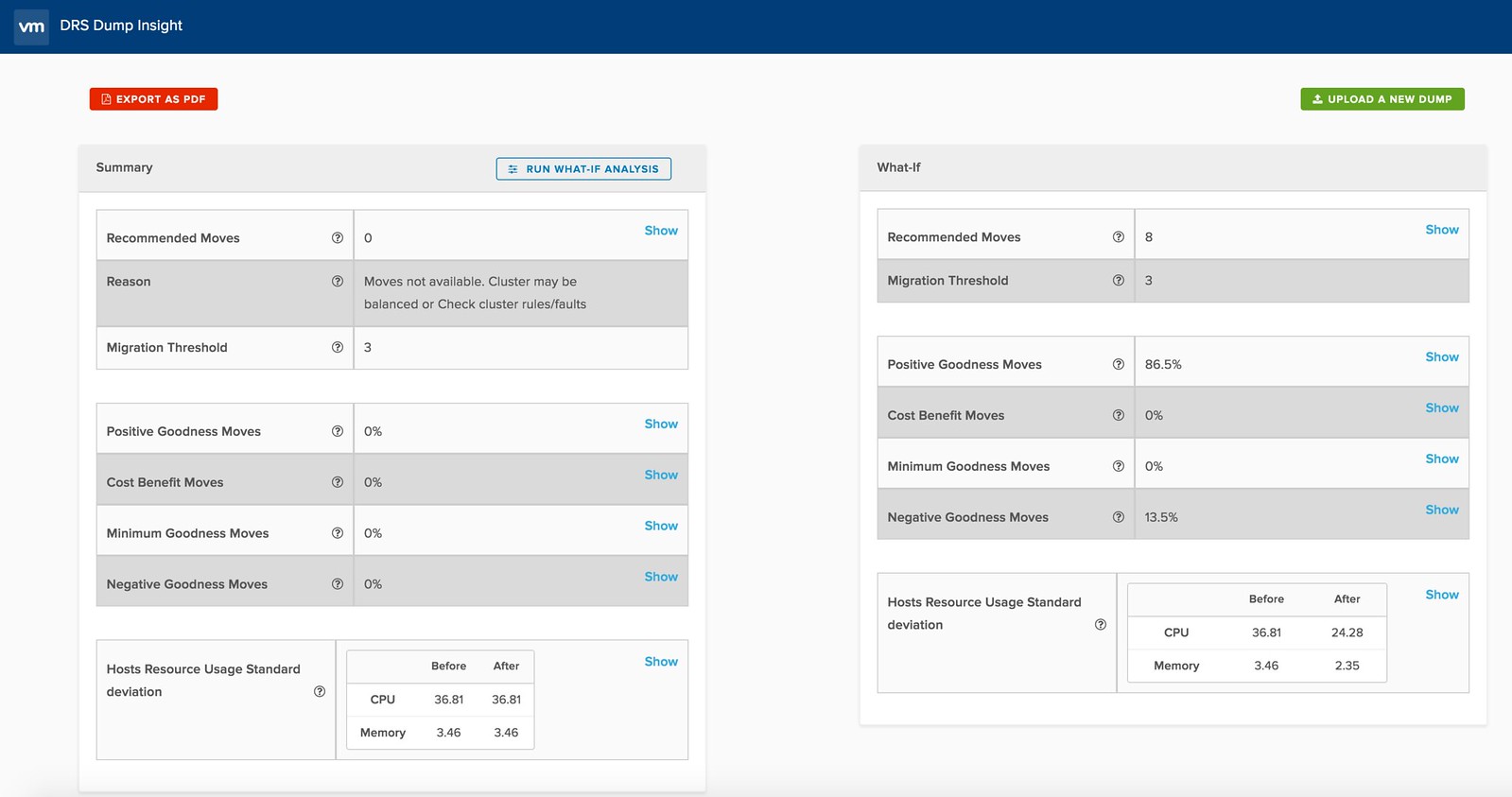
I was just reading up and noticed the DRS Dump Insight solution. It is a SaaS based DRS Dump Analyzer which gives you details around why your cluster is not balanced, or why certain recommendations are not made. Especially the “what if” scenarios are cool if you ask me. You can take a dump and then using the whatif feature check out what would happen to your cluster if for instance all affinity rules were dropped. Or what would happen if the DRS migration threshold is changed, or some advanced settings are used.
You can find some more info about it here, and the SaaS tool here. I hope this will make it in to the product soon in the form of a “health check”… Very useful and insightful! Oh, if you can’t access the website, try it in “Incognito Mode”. Seems there are some issues with the certificate.