Episode 004 is out! This time we talk to Cody Hosterman, Director of Product Management at Pure Storage, about Virtual Volumes aka vVols! Cody shares with us the past, present, and future of vVols. I especially enjoyed his explanations around the benefits of vVols for traditional and cloud-native workload. It is also great to hear that VMware is working with Pure Storage on designing and developing a stretched cluster capability for vVols based environments. Listen below, or via Apple, Google, Spotify etc.
vsan
Announcing the Unexplored Territory Podcast!
 Frank, Johan, and I have been working on this for a few months already, but today I can finally share that a brand new podcast series will be out soon. This bi-weekly podcast (released on Monday) is titled “Unexplored Territory“. We will be discussing topics such as public cloud, virtualization, cloud-native applications, Kubernetes, end-user computing, storage, business continuity, and important (VMware-based) emerging technologies with industry/subject matter experts.
Frank, Johan, and I have been working on this for a few months already, but today I can finally share that a brand new podcast series will be out soon. This bi-weekly podcast (released on Monday) is titled “Unexplored Territory“. We will be discussing topics such as public cloud, virtualization, cloud-native applications, Kubernetes, end-user computing, storage, business continuity, and important (VMware-based) emerging technologies with industry/subject matter experts.
You may wonder, where you will be able to find it/us? Well of course we have a website: UnexploredTerritory.Tech. You can find us on Twitter on @UnexploredPod. You can listen to the podcast via any of your favorite podcast apps: Apple Podcasts, Spotify, Google Podcasts, Overcast, Stitcher, Amazon Music, Stitcher, Pocket Cast. Or use the RSS Feed to add the podcast to your favorite podcast player.
Make sure to subscribe and download the episodes automatically! Our very first guest will be a very special one, we invited VMware’s brand new CTO Kit Colbert to join us, and this episode will be available on Monday the 18th of October! We created a short teaser for the podcast, you can find it in your podcast app or check it out below via the embedded player. We hope everyone will enjoy the podcast, we are looking forward to many great conversations!
vSAN 7.0 U3 enhanced stretched cluster resiliency, what is it?
I briefly discussed the enhanced stretched cluster resiliency capability in my vSAN 7.0 U3 overview blog. Of course, immediately questions started popping up. I didn’t want to go too deep in that post as I figured I would do a separate post on the topic sooner or later. What does this functionality add, and in which particular scenario?
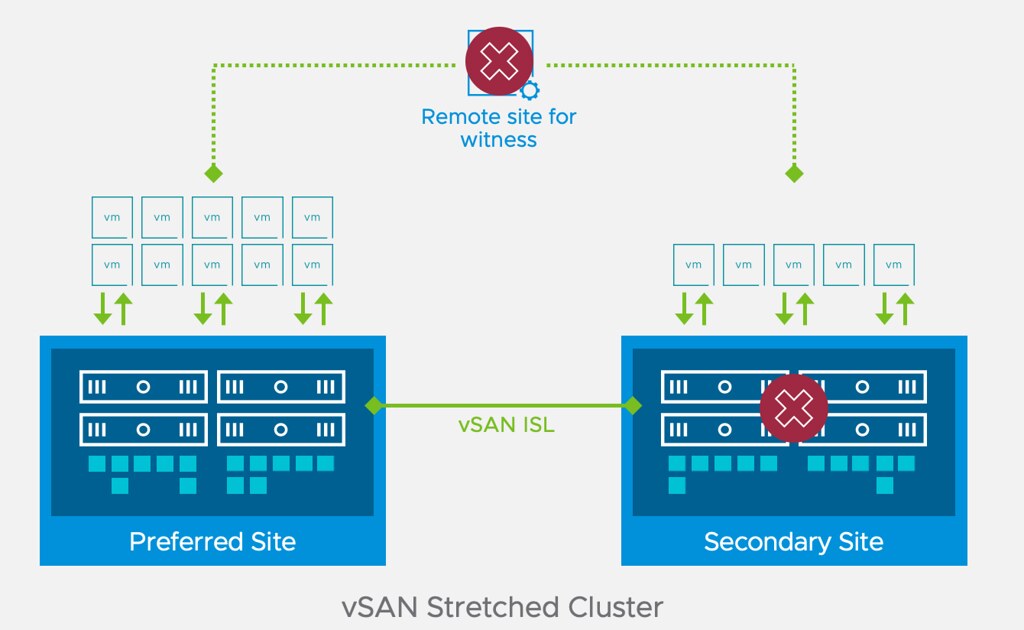
In short, this enhancement to stretched clusters prevents downtime for workloads in a particular failure scenario. So the question then is, what failure scenario? Let’s take a look at this diagram first of a typical stretched vSAN cluster deployment.

If you look at the diagram you see the following: Datacenter A, Datacenter B, Witness. One of the situations customers have found themselves in is that Datacenter A would go down (unplanned). This of course would lead to the VMs in Datacenter A being restarted in Datacenter B. Unfortunately, sometimes when things go wrong, they go wrong badly, in some cases, the Witness would fail/disappear next. Why? Bad luck, networking issues, etc. Bad things just happen. If and when this happens, there would only be 1 location left, which is Datacenter B.
Now you may think that because Datacenter B typically will have a full RAID set of the VMs running that they will remain running, but that is not true. vSAN looks at the quorum of the top layer, so if 2 out of 3 datacenters disappear, all objects impacted will become inaccessible simply as quorum is lost! Makes sense right? We are not just talking about failures right, could also be that Datacenter A has to go offline for maintenance (planned downtime), and at some point, the Witness fails for whatever reason, this would result in the exact same situation, objects inaccessible.
Starting with 7.0 U3 this behavior has changed. If Datacenter A fails, and a few (let’s say 5) minutes later the witness disappears, all replicated objects would still be available! So why is this? Well in this scenario, if Datacenter A fails, vSAN will create a new votes layout for each of the objects impacted. It basically will assume that the witness can fail and give all components on the witness 0 votes, on top of that it will give the components in the active site additional votes so that we can survive that second failure. If the witness would fail, it would not render the objects inaccessible as quorum would not be lost.
Now, do note, when a failure occurs and Datacenter A is gone, vSAN will have to create a new votes layout for each object. If you have a lot of objects this can take some time. Typically it will take a few seconds per object, and it will do it per object, so if you have a lot of VMs (and a VM consists of various objects) it will take some time. How long, well it could be five minutes. So if anything happens in between, not all objects may have been processed, which would result in downtime for those VMs when the witness would go down, as for that VM/Object quorum would be lost.
What happens if Datacenter A (and the Witness) return for duty? Well at that point the votes would be restored for the objects across locations and the witness.
Pretty cool right?!
vSAN 7.0 U3 feature overview
In this blog post, I want to go over the features which have been released for vSAN as part of 7.0 U3. It is not going to be a deep dive, just a simple overview as most features speak for themselves! Let’s list the feature first, and then discuss some of them individually.
- Cluster Shutdown feature
- vLCM support for Witness Appliance
- Skyline Health Correlation
- IO Trip Analyzer
- Nested Fault Domains for 2-Node Clusters
- Enhanced Stretched Cluster durability
- Access Based Enumeration for SMB shares via vSAN File Services
I guess the Cluster Shutdown feature speaks for itself. It basically enables you to power off all the hosts in a cluster when doing maintenance. Even if those hosts contain vCenter Server! If you want to trigger a shutdown, just right click the cluster object, go to vSAN, select “shutdown cluster” and follow the 2-step wizard. Pretty straight forward. Do note, besides the agent VMs, you will need to power-off the other VMs first. (yes, I requested this to be handled by the process as well in the future!)

The Skyline Health Correlation feature is very useful for customers who are seeing multiple alarms being triggered and are not sure what to do. In this scenario, starting with 7.0 U3, vSAN will now understand the correlation between the events and inform you what the issue is (most likely) and show you which other tests it would impact. This should enable you to fix the problem faster than before.
IO Trip Analyzer is also brand new in 7.0 U3. I actually wrote a blog post on the subject separately and included a demo, I would recommend watching that one. But if you just want the short summary, the IO Trip Analyzer basically provides an overview of latency introduced at every layer in the form of a diagram!
Nested Fault Domains for 2-node clusters has been on the “wish list” of some of our customers for a while. It is a very useful feature for those customers who want to be able to tolerate multiple failures even in a 2-node configuration. The feature requires you to have at least 3 disk groups per host, in each of the 2 hosts, and will then enable you to have “RAID-1” across those two hosts and RAID-1 within the host (Or RAID-5 if you have sufficient disk groups). If a host fails, and then a disk fails in the surviving host, the VMs would still be available. Basically a feature for customers who don’t need a lot of compute power (3 hosts or more), but do need added resiliency!
Enhanced Stretched Cluster durability (also applies to 2-node) is a feature that Cormac and I requested a while back. We requested this feature as we had heard from a few customers that unfortunately, they had found themselves in a situation where a datacenter would go offline, followed by the witness going down. This would then result in the VMs (only those which were stretched of course) in the remaining location also be unusable, as 2 out of the 3 parts of the RAID tree would be gone. This would even be the case in a situation where you would have a fully available RAID-1 / RAID-5 / RAID-6 tree in the remaining datacenter. This new feature now prevents this scenario!
Last, but not least, we now have support for Access Based Enumeration for SMB shares via vSAN File Services. What does this mean? Pre vSAN 7.0 U3, if a user had access to a file share the user would be able to see all folders/directories in this share. Starting with 7.0 U3 when looking at the share, only the folders that you have the appropriate permissions for will be displayed! (More about ABE here)
vSAN 7.0 u3: IO Trip Analyzer
In vSAN 7.0 U1 a new feature was introduced called IO Insight. IO Insight basically enabled customers to profile workloads and it provided them with a lot of information around the type of IO the workload was producing. In vSAN 7.0 U3 this is taken one step further with the IO Trip Analyzer. The IO Trip Analyzer provides details around the, yes you guessed it, trip of the IO. It basically informs you about the latency introduced at the various stages of the path the IO has to travel to end up on the capacity layer of vSAN.
Why would you need this? This tool is going to be very useful and will complement IO Insight when it comes to doing performance troubleshooting, or when it comes to getting a better understanding of the IO path. IO Trip Analyzer can be easily enabled by going to the “Monitor” section of the VM you want to enable it for.

You simply click “Run new test” and then specify for how long you want to analyze the VM (between 5 and 60 minutes). When the specified amount has passed you simply click on “View Result” and this will then provide you a diagram of the VM and its components.

When you then click on one of the dots, you will be able to see what kind of latency is introduced on the layer. It will provide you a potential cause for the latency and it will provide you some insights in terms of how you can potentially resolve the latency. Also, if there’s a significant amount of latency introduced then of course the diagram will show this through colors for the respective layer where the latency is introduced.

Before I share the demo, I should probably mention that there are some limitations in this first release of the IO Trip Analyzer (Not supported: Stretched Clusters, CNS persistent volumes, iSCSI etc) but I suspect those limitations will be lifted with every follow-up release of vSAN. I truly feel that this is a big improvement when it comes to performance troubleshooting, and I can’t wait to see what the vSAN team is planning for the future of this release.