Yesterday I posted the DRS Deepdive. One of the questions still left open was how DRS decides which VM to move to create a balance cluster. After a lot of digging for non-NDA info I found this “procedure” in a VMworld presentation(TA16) amongst some other cool info.
The following procedure is used to form a set of recommendations to correct the imbalanced cluster:
While (load imbalance metric > threshold) {
move = GetBestMove();
If no good migration is found:
stop;
Else:
Add move to the list of recommendations;
Update cluster to the state after the move is added;
}
Step by step in plain English:
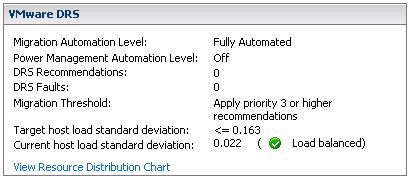
While the cluster is imbalanced (Current host load standard deviation > Target host load standard deviation) select a VM to migrate based on specific criteria and simulate a move and recompute the “Current host load standard deviation” and add to the migration recommendation list. If the cluster is still imbalanced(Current host load standard deviation > Target host load standard deviation) repeat procedure.
Now how does DRS select the best VM to move? DRS uses the following procedure:
GetBestMove() {
For each VM v:
For each host h that is not Source Host:
If h is lightly loaded compared to Source Host:
If Cost Benefit and Risk Analysis accepted
simulate move v to h
measure new cluster-wide load imbalance metric as g
Return move v that gives least cluster-wide imbalance g.
}
Again in plain English:
For each VM check if a VMotion to each of the hosts which are less utilized than source host would result in a less imbalanced cluster and meets the Cost Benefit and Risk Analysis criteria. Compare the outcome of all tried combinations(VM<->Host) and return the VMotion that results in the least cluster imbalance.
This should result in a migration which gives the most improvement in terms of cluster balance, in other words: most bang for the buck! This is the reason why usually the larger VMs are moved as they will most likely decrease “Current host load standard deviation” the most. If it’s not enough to balance the cluster within the given threshold the “GetBestMove” gets executed again by the procedure which is used to form a set of recommendations.
Now the next question would be what does “Cost Benefit” and “Risk Analysis” consist of and why are we doing this?
First of all we want to avoid a constant stream of VMotions and this will be done by weighing costs vs benefits vs risks. These consists of:
- Cost benefit
Cost: CPU reserved during migration on t he target host
Cost: Memory consumed by shadow VM during VMotion on the target host
Cost: VM “downtime” during the VMotion
Benefit: More resources available on source host due to migration
Benefit: More resources for migrated VM as it moves to a less utilized host
Benefit: Cluster Balance - Risk Analysis
Stable vs unstable workload of the VM (historic info used)
Based on these consideration a cost-benefit-risk metric will be calculated and if this has an acceptable value the VM will be consider for migration.
I will consolidate both post in a single blog page today to make it easier to find!