Episode 004 is out! This time we talk to Cody Hosterman, Director of Product Management at Pure Storage, about Virtual Volumes aka vVols! Cody shares with us the past, present, and future of vVols. I especially enjoyed his explanations around the benefits of vVols for traditional and cloud-native workload. It is also great to hear that VMware is working with Pure Storage on designing and developing a stretched cluster capability for vVols based environments. Listen below, or via Apple, Google, Spotify etc.
vmfs
What is this Catalog folder on my datastore?
A question popped up on our internal slack earlier these days, and as I didn’t find anything online for it I figured I would write a quick article. When you look at your datastore, you may find various folders. Some you will recognize like the “.vSphere-HA” folder structure, which is used by vSphere HA, others you may not recognize, like the folder called “catalog” (see screenshot below), which has folders like “shard”, “mutex”, “tidy”, and “vclock” in it. The folder “catalog”, and all folders underneath, are created automatically when you use First Class Disk’s (FCD). FCD uses the folder structure to store it’s metadata in it. So please do not remove/delete or touch these folders. If you like to know more about FCD, make sure to read Cormac’s post on it.

Oh and if wonder why you are using FCD in the first place, it is often used for Kubernetes “persistent volumes”. So if you are using Tanzu/Kubernetes and have persistent volumes, chances are you are using FCD, which would result in those folders on your datastore. Nothing to worry about. 🙂
DQLEN changes, what is going on?
I had a question this week on twitter, it was about the fact that DQLEN changes to values well below it was expected to be (30) in esxtop for a host. There was latency seen and experienced seen for VMs so the question was why is this happening and wouldn’t a lower DQLEN make things worse?
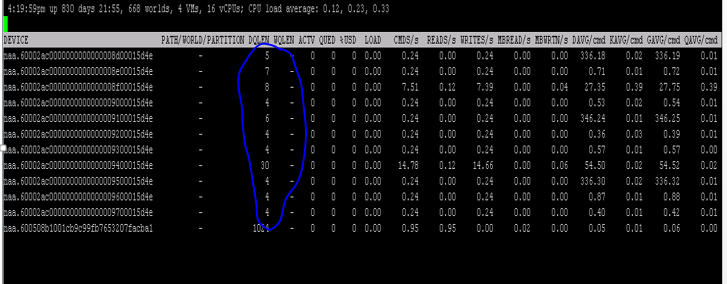
My first question: Do you have SIOC enabled? The answer was “yes”, and this is (most likely) what is causing the DQLEN changes. (What else could it be? Adaptive Queueing for instance.) When SIOC is enabled it will automatically change DQLEN when the configured latency threshold is exceeded based on the number of VMs per host and the number of shares. DQLEN will be changed to ensure a noisy neighbor VM is not claiming all I/O resources. I described how that works in this post in 2010 on Storage IO Fairness.
How do you solve this problem? Well, first of all, try to identify the source of the problems, this could be a single (or multiple) VMs, but it could also be that in general, the storage array is running at its peak constantly or backend services like replication is causing a slowdown. Typically it is a few (or one) VMs causing the load, try to find out which VMs are pushing the storage system and look for alternatives. Of course, that is easier said than done, as you may not have any expansion possibilities in the current solution. Offloading some of the I/O to a caching solution could also be an option (Infinio for instance), or replace the current solution with a more capable system is another one.
vSphere 6.5 what’s new – VMFS 6 / Core Storage
I haven’t spend a lot of time looking at VMFS lately. I was looking in to what was new for vSphere 6.5 and then noticed a VMFS section. Good to see there is still being worked on new features and functionality for the core vSphere file system. So what is new with VMFS 6:
- Support for 4K Native Drives in 512e mode
- SE Sparse Default
- Automatic Space Reclamation
- Support for 512 devices and 2000 paths (versus 256 and 1024 in the previous versions)
- CBRC aka View Storage Accelerator
Lets look at them one by one, I think support for 4K native drives in 512e mode speaks for itself. Sizes of spindles keep growing and these new “advanced format” drives come with a 4K byte sector instead of the usual 512 byte sector, which is primarily for better handling of media errors. As of vSphere 6.5 this is now fully supported but note that for now it is only supported when running in 512e mode! The same applies to Virtual SAN in the 6.5 release, only supported in 512e mode. This basically means that 512 byte sectors is being emulated on a 4k drive. Hopefully we will have more on full support for 4Kn for vSphere/VSAN soon.
From an SE Sparse perspective, right now SE Sparse is used primarily View and for LUNs larger than 2TB. When on VMFS 6 the default will be SE Sparse. Not much more to it than that. If you want to know more about SE Sparse, read this great post by Cormac.
Automatic Space Reclamation is something that I know many of my customers have been waiting for. Note that this is based on VAAI Unmap which has been around for a while and allows you to unmap previously used blocks. In other words, storage capacity is reclaimed and released to the array so that when needed other volumes can use these blocks. In the past you needed to run a command to reclaim the blocks, now this has been integrated in the UI and can simply be turned on or off. Oh, you can find this in the UI when you go to your datastore object and then click configure, you can set it to “none” which means you disable it, or you set it to low in the UI as shown in the screenshot below.
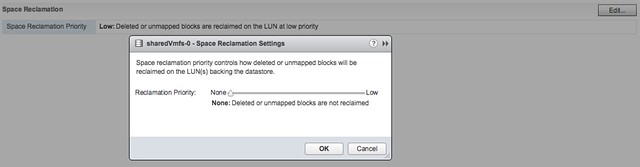
If you prefer “esxcli” then you can do the following to get the info of a particular datastore (sharedVmfs-0 in my case) :
esxcli storage vmfs reclaim config get -l sharedVmfs-0 Reclaim Granularity: 1048576 Bytes Reclaim Priority: low
Or set the datastore to a particular level, note that using esxcli you can also set the priority to medium and high if desired:
esxcli storage vmfs reclaim config set -l sharedVmfs-0 -p high
Next up, support for 512 Devices and 2000 Paths. In previous versions the limit was 256 devices and 1024 paths and some customers were hitting this limit in their cluster. Especially when RDMs are used or people have a limited number of VMs per datastore, or maybe 8 paths to each device are used it becomes easy to hit those limits. Hopefully with 6.5 that will not happen anytime soon. On the other hand, personally I would hope more and more people are considering moving towards either VSAN or Virtual Volumes.
This is one I accidentally ran in to and not really directly related to VMFS but I figured I would add it here anyway otherwise I would forget about it. In the past CBRC aka View Storage Accelerator was limited to 2GB of memory cache per host. I noticed in the advanced settings that it now is set to 32GB, which is a big difference compared to the 2GB in previous releases. I haven’t done any testing, but I assume our EUC team has and hopefully we will see some good performance data on this big increase soon.
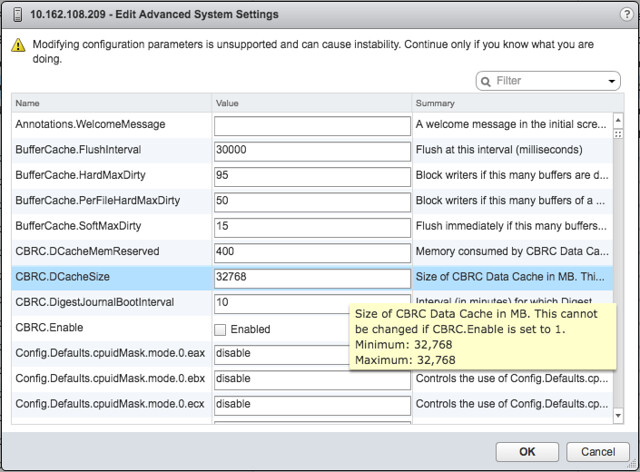
And that was it… some great enhancements in the core storage space if you ask me. And I am sure there was even more, and if I find out more details I will share those with you as well.
VMFS Deepdive Paper
I received this question yesterday about material around VMFS. Of course I pointed them to the white paper Cormac recently published, which is an awesome read. But I also had this other link laying around which I forgot to share with the world. This paper is written by Satyam Vaghani (former VMware Principal Engineer, now CTO of PernixData) and is a true deepdive on VMFS and topics like locking / metadata. Do note that this paper was written in the VMFS 3.x timeframe, and as such some of the concepts might have changed.
Nevertheless, a very interesting read if you ask me! Make sure to pick up a copy here.