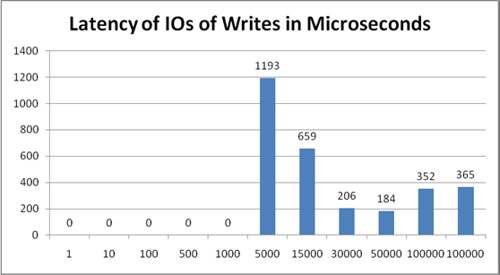
This week we(Frank Denneman and I) played around with vscsiStats, it’s a weird command and hard to get used to when you normally dive into esxtop when there are performance issues. While asking around for more info on the metrics and values someone emailed us nfstop. I assumed it was NDA or at least not suitable for publication yet but William Lam pointed me to a topic on the VMTN Communities which contains this great script. Definitely worth checking out. This tool parses the vscsiStats output into an esxtop format. Below a screenshot of what that looks like: