VMware has just released version 1.1 of the VMware Desktop Reference Architecture Workload Simulator (RAWC). As I know many of my readers are actively working on View projects I thought it might be of interest for you.
VMware Desktop Technical Marketing & TS Research Labs are jointly announcing the availability of VMware Desktop Reference Architecture Workload Simulator (RAWC) version 1.1. With RAWC 1.1, Solution Providers can better anticipate and plan for infrastructure requirements to support successful VMware View deployments for Windows 7 Migration.
RAWC 1.1 now simulates user workloads in Windows 7 environments and can be used to validate VMware View designs to support Windows 7 Migrations. RAWC 1.1 supports the following desktop applications in Windows 7 and Windows XP environments: Microsoft Office 2007, Microsoft Outlook, Microsoft Internet Explorer, Windows Media Player, Java code compilation simulator, Adobe Acrobat, McAfee Virus Scan, and 7-Zip.
RAWC 1.1 also includes bug fixes and several enhancements in test run configurations, usability and user interface. Please see RAWC 1.1 product documents for more details.
VMware partners can download RAWC 1.1 software and the product documents from VMware Partner Central:Sales Tools > Services IP.
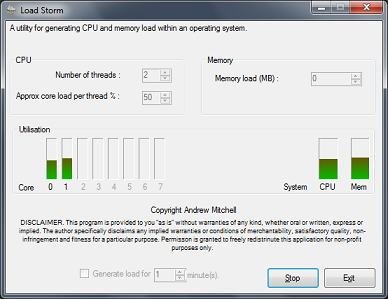
 Saw some tweets wanting ways to generate load in a VM. Here’s one I prepared earlier:
Saw some tweets wanting ways to generate load in a VM. Here’s one I prepared earlier: