I was talking to the HA team this week, specifically about the upcoming HA book. One thing they mentioned is that people still seem to struggle with the concept of admission control. This is the reason I wrote a whole chapter on it years ago, yet there still seems to be a lot of confusion. One thing that is not clear to people is the percentage calculations. We have some customers with VMs with extremely large reservations, in that case instead of using the “slot policy” they typically switch to “percentage based policy”. Simply as the percentage based policy is a lot more flexible.
However, recently we have had some customers that hit the following error message:
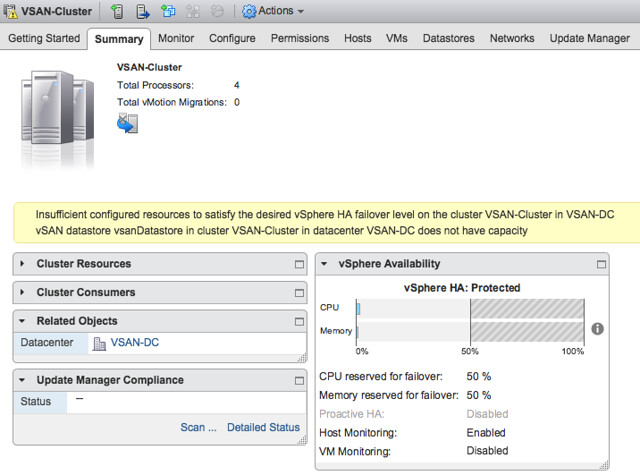
Insufficient configured resources to satisfy the desired vSphere HA failover level on the cluster
This error message, in the case of these particular situations (yes there was a bug as well, read this article on that), set the percentage lower than what would equal a full host. In other words, in a 4 host environment, a single host would equal 25%. In some cases, customers would set the percentage to a value lower than 25%. I am personally not sure why anyone would do this as it contradicts the whole essence of admission control. Nevertheless, it happens.
This message indicates that you may not have sufficient resources, in the case of a host failure, to restart all the VMs. This of course is the result of the percentage being set lower than the value that would equal a single host. Note though, this does not stop you from powering on new VMs. You will only be stopped from powering on new VMs when you exceed the available unreserved resources.
So if you are seeing this error message, please verify the configured percentage if you set it manually. Ensure that at a minimum it equals the largest host in the cluster.
** back to finalizing the book **