I had question today about using the advanced settings to set a minimal amount of resources that HA would use to do the admission control math with. Many of us have used these advanced settings das.vmMemoryMinMB and das.vmCpuMinMHz to dictate the slot size when no reservations were set in an environment where the “host failures” admission control policy was used. However what many don’t appear to realize is that this will also work for the Percentage Based admission control policy.
If you want to avoid extreme overcommitment and want to specify a minimal amount of resources that HA should use to do the math with then even with the Percentage Based admission control policy you can use these settings. In the case where your VM reservation does not exceed the value specified, the value is used to do the math with. In other words if you set “das.vmMemoryMinMB” to 2048, it will use 2048 to do the math with unless the reservation set on the VM is higher.
I did a quick experiment in my test lab which I had just rebuilt. Without das.vmMemoryMinMB and two VMs running (with no reservation) I had 99% Mem Failover Capacity as shown in the screenshot below:
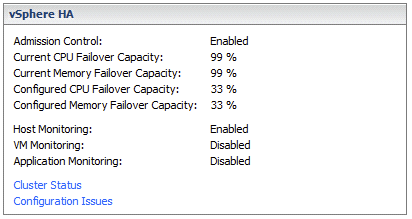
With das.vmMemoryMinMB set to 20480, and two VMs running, I had 78% Mem Failover Capacity as shown in the screenshot below:
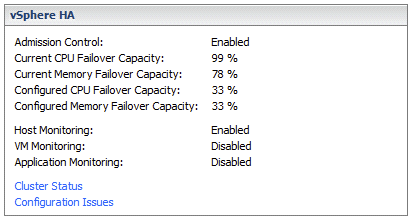
I guess that proves that you can use das.vmMemoryMinMB and das.vmCpuMinMHz to influence Percentage Based admission control.
