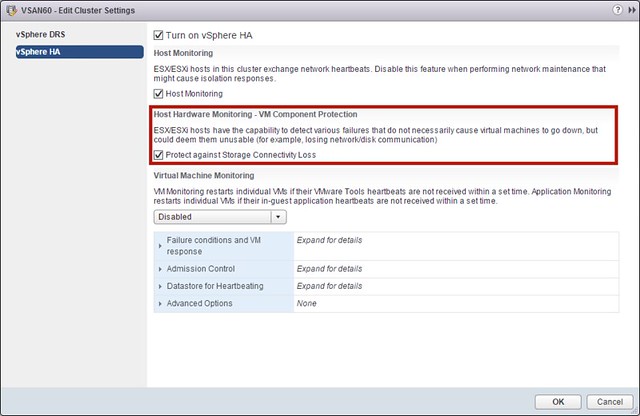
Bumped in to this a billion times by now, and I wouldn’t recommend applying this in production but for your lab when you need to take clean screenshots it works great. I’ve mentioned this setting before but as it was part of a larger article it doesn’t stand out when searching so I figured I would dedicate a short and simple article to it. Here is what you will need to do if you see the following message in the vSphere Web Client: this host currently has no network management redundancy.
- Go to your Cluster object
- Go to Settings
- Go to “vSphere HA”
- Click “Edit”
- Add an advanced setting called “das.ignoreRedundantNetWarning”
- Set the advanced setting to “true”
- On each host right click and select “reconfigure for vSphere HA”
This is what it should look like in the UI:
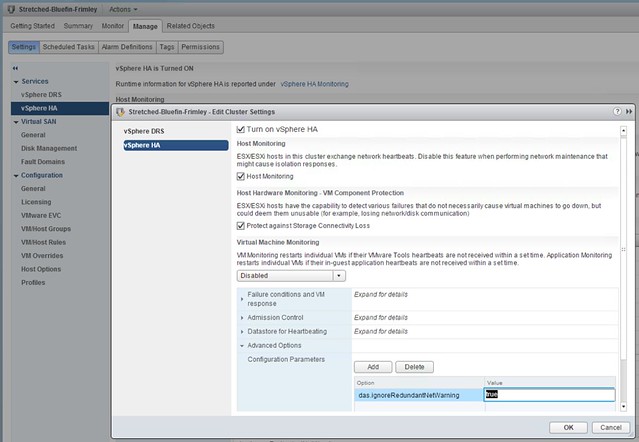
You can also do this in PowerCLI by the way, note that “Stretched-Bluefin-Frimley” is the name of my cluster.
New-AdvancedSetting -Entity Stretched-Bluefin-Frimley -type ClusterHA -Name "das.ignoreRedundantNetWarning" -Value "true" -force