Short answer, yes 2-node configurations with vSAN 8.0 ESA support Nested Fault Domains. Meaning that when you have a 2-node configuration you can also protect your data within each host with RAID-1, RAID-5, or RAID-6! The configuration of this is pretty straightforward. You create a policy with “Host Mirroring” and select the protection you want in each host. The screenshot below demonstrates this.
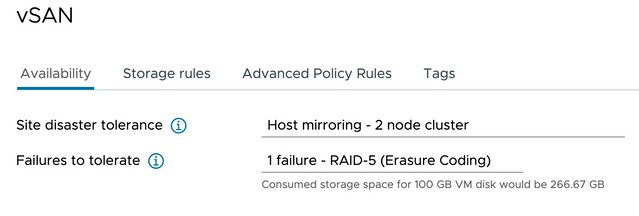
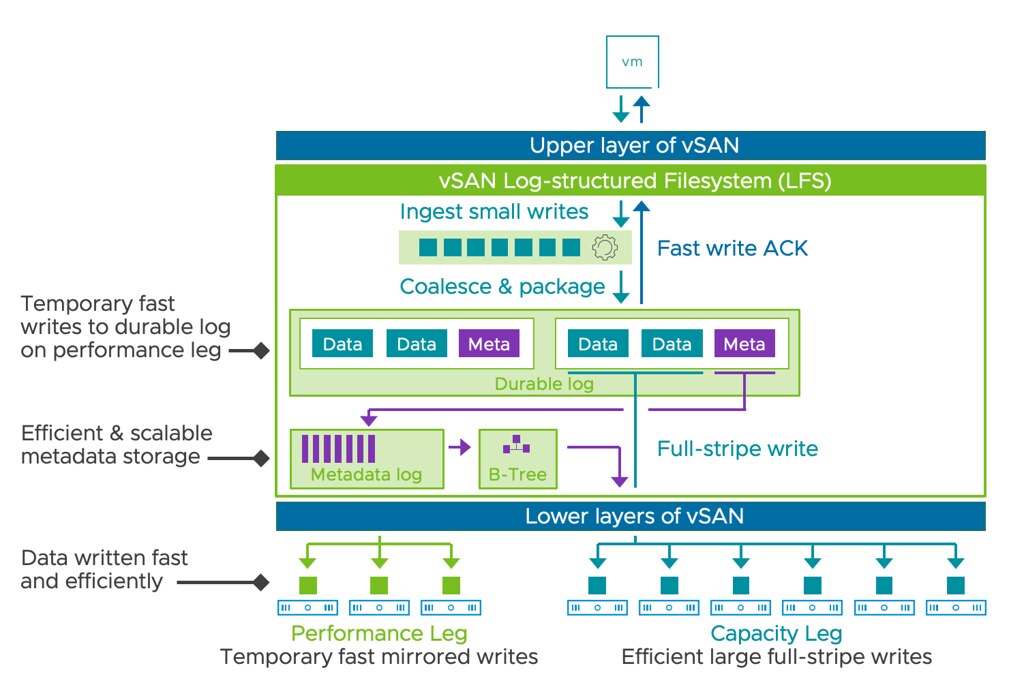
In the above example, I mirror the data across hosts and then have a RAID-5 configuration within each host. Now when I create a RAID-5 configuration within each host I will get the new vSAN ESA 2+1 configuration. (2 data blocks, 1 parity block) If you have 6 devices or more in your host, you can also create a RAID-6 configuration, which is 4+2. (4 data blocks, 2 parity blocks) This provides a lot of flexibility and can lower the overhead when desired compared to RAID-1. (RAID-1 = 100% overhead, RAID-5 = 50% overhead for 2+1, RAID-6 = 50% overhead) When you use RAID-5 and RAID-6 and look at the layout of the data it will look as shown in the next two screenshots, the first screenshot shows the RAID-5 configuration, and the second the RAID-6 configuration.
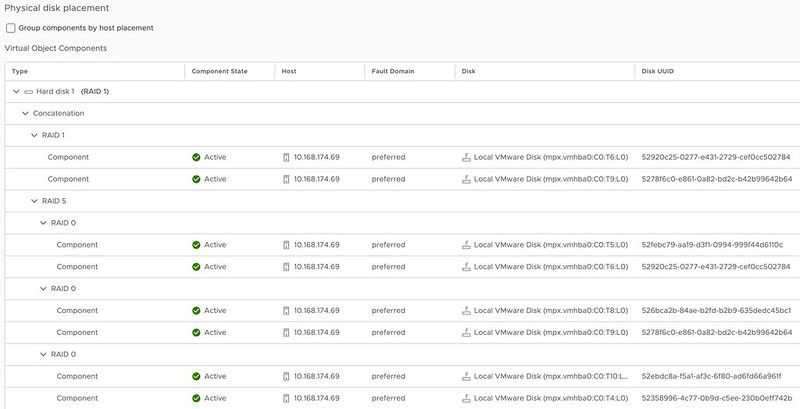
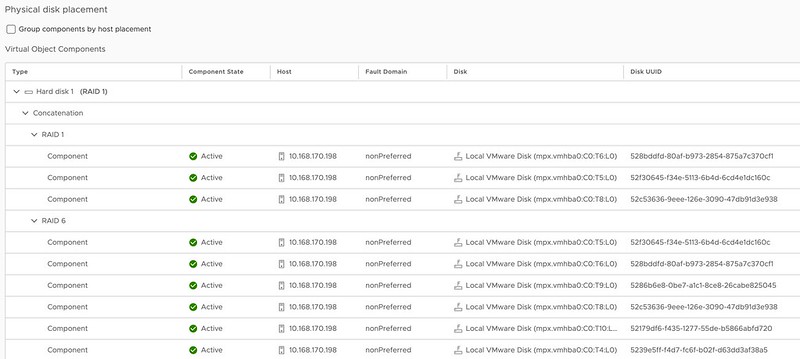
One thing you may wonder when looking at the screenshots is why they also have a RAID-1 configuration for the VMDK object, this is the “performance leg” that vSAN ESA implements. For RAID-5, which is “FTT=1”, this means you get 2 components. For RAID-6, which is FTT=2, this means you will get 3 components so you can tolerate 2 failures.
I hope that helps answer some of the questions folks had on this subject!