I was playing in the lab for our upcoming vSphere Clustering Deepdive book and I ran in to this error when powering on a VM. I had never seen it before myself, so I was kind of surprised when I figured out what it was referring to. The error message is the following:
Module MonitorLoop power on failed when powering on VM
Think about that for a second, if you have never seen it I bet you don’t know what it is about? Not strange as the message doesn’t give a clue.

f you go to the event however there’s a big clue right there, and that is that the swap file can’t be extended from 0KB to whatever it needs to be. In other words, you are probably running out of disk space on the device the VM is stored on. In this case I removed some obsolete VMs and then powered on the VM that had the issue without any problems. So if you see this “Module MonitorLoop power on failed when powering on VM” error, check your free capacity on the datastore the VM sits on!
More details:
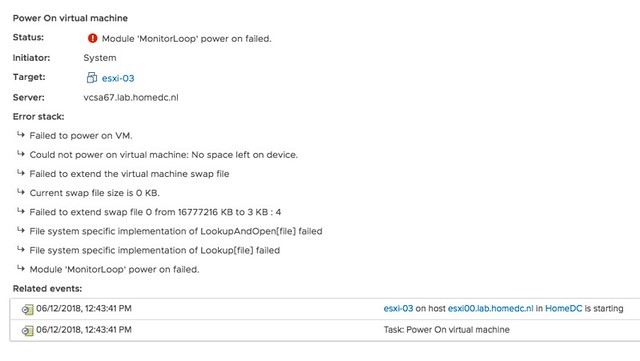
Strange error message, for a simple problem. Yes, I will file a request to get this changed.