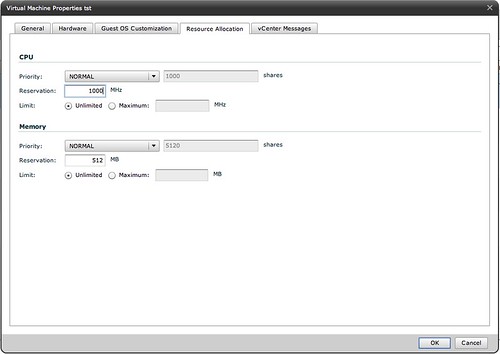
I had this question coincidentally two times of the last 3 weeks and I figured that it couldn’t hurt explaining it here as well. The question on the VMTN community was as follows:
on 13 sec: a host which hears from none of the partners will ping the isolation address
on 14 sec: if no reply from isolation address it will trigger the isolation response
on 15 sec: the host will be declared dead from the remaining hosts, this will be confirmed by pinging the missing host
on 16 sec: restarts of the VMs will beginMy first question is: Do all these timings come from the das.failuredetectiontime? That is, if das.failuredetectiontime is set to e.g. 30000 (30 sec) then on the 28th second a potential isolated host will try to ping the isolation address and do the Isolation Response action at 29 second?
Or is the Isolation Response timings hardcoded and always happens at 13 sec?
My second question, if the answer is Yes on above, why is the recommendation to increase das.failuredetectiontime to 20000 if having multiple Isolation Response addresses? If the above is correct then this would make to potential isolated host to test its isolation addresses at 18th second and the restart of the VMs will begin at 21 second, but what would be the gain from this really?
To which my answer was very short fortunately:
Yes, the relationship between these timings is das.failuredetectiontime.
Increasing the das.failuredetectiontime is usually recommended when an additional das.isolationaddress is specified. the reason for this is that the “ping” and the “result of the ping” needs time and by added 5 seconds to the failure detection time you allow for this test to complete correctly. After which the isolation response could be triggered.
After having a discussion on VMTN about this and giving it some thought and bouncing my thoughts with the engineers I came to the conclusion that the recommendation to increase das.failuredetectiontime with 5 seconds when multiple isolation addresses are specified is incorrect. The sequence is always as follows regardless of the value of das.failuredetectiontime:
- The ping will always occur at “das.failuredetectiontime -2”
- The isolation response is always triggered at “das.failuredetectiontime -1”
- The fail-over is always initiated at “das.failuredetectiontime +1”
The timeline in this article explains the process well.
Now, this recommendation to increase das.failuredetectiontime was probably made in times where many customers were experiencing network issues. Increasing the time decreases the chances of running in to an issue where VMs are powered down due to a network outage. Sorry about all the confusion and unclear recommendations.