Author: Craig Risinger
Craig is a Consulting Architect working for VMware PSO in the US and a fellow member of the VCDX Panel. During the VCDX panels in Las Vegas a bunch of us had a discussion around Resource Pools and shares and this led to the following article. Thanks Craig! PS: I also wrote an article on this topic.
We run into this on a daily basis; Misunderstanding of the “shares” concept in combination with resource pools. To start with a bold statement: A few VMs in a Low-shares Resource Pool can outperform each of many VMs in a High-shares Resource Pool. How is this possible you might ask.
Resources are divided at the Resource Pool level first. Each Resource Pool is like a pie whose size determines amount of resources usable (during contention). Then that pie is subdivided among the VMs in the pool. A Resource Pool applies to all its VMs collectively. Thus a smaller pie divided among fewer VMs can yield more resources per VM than a larger pie divided by even more VMs.
An example will make it more clear:
Consider a “Test” Resource Pool with 1000 shares of CPU and 4 VMs, vs. a “Production” Resource Pool with 4000 shares of CPU and 50 VMs.
“Test” 1000 shares, 4 VMs => 250 units per VM (small pie, a few big slices):
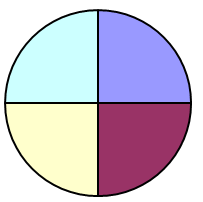
“Production” 4000 shares, 50 VMs => 80 units per VM (bigger pie, many small slices):
I guess this makes it really obvious that shares might not always give you the results you expected it would.
Note that shares matter only when there is contention. If there are no Reservations or Limits defined, when there’s no resource shortage, every VM gets everything it requests.
I’m pretty sure this came out of my defense. Craig challenged me. I’m pretty sure I defended it correctly.
Not that I can speak for every situation, but I know for our shop using reservations at the resource pool level make the most sense. We do not want to affect slot sizing with reservations, yet want to make sure our production VMs receive a certain amount of dedicated resources if they need it. Shares on a per VM level make more sense or at a vApp level since (at least for us) a vApp consists of only a few servers it is easier to calculate share sizing. I still think per VM shares is best, with reservations at the resouce pool level then vApp level with expandable setting enabled. I think the accidental reversal of intentions happens a lot with shares at the resource pool level.
Keep in mind that outside of a RP itself, shares on a VM reset when it moves from host to host. Even if you hard code a VM from Normal 1000 shares to have 8000 shares, it will reset as soon as you vMotion or migrate it. Shares are a great tool and can make a huge difference in performance on higher density loads, but you really have to manage them. I miss Virtugo, whom back in the day could really make a big difference in performance just by managing shares.
I just finished up the beta design class and the instructor let us know about the implications of resource pools. It seems that a lot of people use them for vm organization which can lead to problems. He pointed out exactly what you mentioned above and I’m sure it affects a lot of people who use them. Thanks!
Ah interesting, I can see how shares would reset from host to host during a migration. I guess I will have to start setting shares at the vApp level, perhaps that is a better place for them in my environment or maybe I have no use for them at all. Contention isn’t really an issue anyway unless I had more than one host failure D:.
I’ve tried representing this requirement below a few different ways and the only way I’ve gotten it to work is a way in which I don’t think is best (yet it seems to work, ie, make people happy, so it’s what we go with). Here’s the requirement: If there is contention (either because utilization is bumping up against resource pool limits or physical host resource limits) the “Production” VM(s) will always win and the “Test” VM(s) will always lose. Perhaps a better, more precise, way to put it is: “If there is a “loser” in the “contention race” it will always be a “Test” VM.
Now I understand there may not be a perfect configuration to match that requirement EXACTLY but over the years I’ve tried to come up with the best representation of that as possible. So far the only layout I’ve found that works (ie, people aren’t calling and complaining) is this:
Finance buys a VM host with 8x3Ghz CPU so I create this:
Finance Resource Pool: “FinanceProduction” (shares: Normal, reservation: 24000, limit: 24000 * 1.1, 10% cushion because I’m such a nice guy)
VM: ProdVM1
VM: ProdVM2
VM: ProdVM3
Sub Resource Pool: “FinanceTest” (shares: LOW, reservation: 0, limit: )
VM: TestVM1
VM: TestVM2
VM: TestVM3
And for every other business unit in my company that purchases VM hosts, we add that host into our Cluster and basically give them back a “virtual host” (aka, their own Resource Pool) where we guarantee them they’ll get the resources they paid for plus 10% (using reservations and limits).
I think this work okay, but in my mind it punishes “Test” VMs too much (like, “Test” VMs won’t just be the losers, they’ll be strapped down and beaten to a pulp). In the past I thought moving the Sub Resource Pool “FinanceTest” out and making it a top-level Resource Pool would be a better implementation of the requirement I’m shooting for, but when I do that, the PROD people start calling my office, fast.
Any better suggestions?
Another point of clarification:
Those relative cpu/memory “share” values get utilized at the physical host layer, right? and not the Resource Pool layer. In other words, each physical host is running, say, 20 VMs and of those 20 there are different shares assigned to various VMs (some are “HIGH” others “NORMAL” and others “LOW”) due to the fact that those 20 are broken up into various Resource Pools. Regardless of the reservations guaranteed to any particular Resource Pool, if VM1 on VMHOST1 is “HIGH” shares and VM2 on that same VMHOST1 is “LOW” shares then VM2 will spend more time in “CPU Ready” land than VM1, right? While cpu/memory shares can get configured at the Resource Pool level, it seems to me that they actually MATTER at the physical host level (they are relative to the VMs on the particular ESX host, NOT the particular Resource Pool they are a part of).
what happens if you define the resource shares using “High”, “Medium” and “Low”? I thought those values dynamically adjusted based on the workload of the ESX host?
It’s certainly not dynamical! It’s in a 4:2:1 ratio.
@Benny:
Re “Regardless of the reservations guaranteed to any particular Resource Pool, if VM1 on VMHOST1 is “HIGH” shares and VM2 on that same VMHOST1 is “LOW” shares then VM2 will spend more time in “CPU Ready” land than VM1, right?”
No, that’s wrong.
First of all, forget about Reservations. That just complicates the discussion. Let’s just talk about RPs and shares.
Shares can be defined at the RP level.
Shares can be defined at the VM level, independently of what shares at the RP are. (RP-Prod can have 1/3 VMs at “High” shares, 1/3 at “Normal”, and 1/3 at “Low” shares at the VM level.)
When there’s contention, resources are divided at the RP level first.
You cannot compare “High” shares on VM-P1 in RP-Prod and “Low” shares on VM-T1 in RP “Test” and say VM-P1 always runs better. Shares can be directly compared only among siblings. If you want to compare shares among VMs that are in different resource pools, the shares _at the RP level_ provide a weighting.
Never forget about reservations, the whole problem comes up because you’re using shares when you should be using reservations.
Take a look at my post which shows where reservations address the requirement you have to guarantee resources to production VMs
http://demitasse.co.nz/wordpress2/2010/02/shares-are-abut-shortages-reservations-are-guarantees/
Please, I am researching since september 09 on a VMware ESX issue, because I moved a simple Apache-PHP-mysql server from a physical server to a VM. As soon as I have 50 to 100 HTML-page requests, the server times out or needs 20 seconds to serve a page that takes 0.5 secs on the physical server.
On our ESX cluster we have 5 servers with about 20 VMs on each. Our ESX admin says there is no need to build Resource Pools because every VM gets “dynamically” as much CPU-cicles/resources as needed, as Michael said in his post above.
So what’s about all those shares (high on my VM), Reservation (0 MHz on my VM), Limit (unlimited on my VM), Memory shares (normal and 8GB on my VM), Memory Reservation (0 MB on my VM), Memory Limit (unlimited on my VM), Advanced CPU Hyper Threading (hyperthreaded core sharing: Any on my VM), Processor Affinity (no affinity on my VM)? I seem to get not enough resources independently of those settings, even reducing the number of CPUs to 1 and back to 4 does not make any difference.
Here (http://www.vmware.com/products/esx/index.html) they say: “VMware ESX and ESXi set the record in virtual performance delivering up to 8,900 db transactions per second, 200,000 I/O operations per second, and up to 16,000 Exchange mailboxes per host.” So WHY can I not get to work my simple SUSE 11 server with apache-php-mysql on that VM??
I apologize because I am not an ESX-engineer, but I start to think that our ESX-admin is not one either or in any case not an experienced one. Any hints would be greately appreciated.
It’s really difficult to give an answer when I don’t know what the actual root cause is of the problem. It can be anything from basic over-provisioning to for instance a storage issue. I recommend you read my esxtop article and look at:
– %RDY
– QUED
– DAVG
– KAVG
and memory consumption in general, swapping etc.
Unfortunately I do not understand the technical abbreviations (%RDY, QUED, etc.) But I can give you more details if it helps:
– HP Blade-System with 5 Servers with 2 Intel Xeon Quad-Core each at 1.86GHz
– Lots of RAM, 60GB on each server
– Lots of SAN Disks/Luns, 9 LUNs at 1TB each
– standard installation, no resource pools, every VM unlimited CPU and 4-8GB RAM
We were sold this very expensive system for a professional use in our university and I think it is a scandal that our most productive VMs show very very poor performance.
I just read the article on RESERVATIONS (http://demitasse.co.nz/wordpress2/2010/02/shares-are-abut-shortages-reservations-are-guarantees/), so should I ask our ESX-Admin to create resource-pools with reservations on it?
Note: we are not talking about fine-tuning to get the last microsecond out of it, we are at a ridiculous level of 50-100 html-page requests causing our production servers to time-out or to return a page after 10-15 seconds!
OK, I had a look at the esxtop article and understand now the abbreviations.
Starting tomorrow I will do some tests with reservations and resource pools.
Wanting to determine how one could use Resource Groups without encountering the “Priority-Pie Paradox,” I decided to set up a test environment to find a solution. From reading responses to this thread and other blogs on this topic, I thought the solution was going to be to use reservations and not shares. I was very surprised to learn that it is not possible to ignore shares, because if you do, you will encounter the Priority-Pie Paradox. To help explain, I set up the following test scenario:
ESX Host – 8664 MHz Total CPU Capacity
RP1 – Shares = Normal; Reservation = 1444 MHz
RP2 – Shares = Normal; Reservation = 5776 MHz (also tried 7220 MHz)
There are 6 identical VMs with 2 of them in RP1 and the remaining 4 in RP2.
Running a modified cpubusy.vbs, members of RP2 (server1 – server4) take 5 seconds to complete each sine calculation and members of RP1 (server5 and server6) take 3 seconds. The esxtop results follow:
ID GID NAME NWLD %USED %RUN %SYS %WAIT %RDY
992089 992089 server5 4 96.81 97.05 0.01 295.04 1.98
992097 992097 server6 4 96.56 96.12 0.01 294.94 3.01
852150 852150 server3 4 49.02 49.12 0.00 293.63 51.31
852059 852059 server2 4 49.00 49.13 0.00 294.11 50.84
852435 852435 server4 4 48.94 49.06 0.00 293.63 51.38
909643 909643 server1 4 48.51 48.82 0.01 293.62 51.62
Even though RP2 has a higher CPU reservation, the members of RP1 perform better because they have bigger “pie pieces,” resulting in lower CPU Ready times. When I change the shares on RP1 to Low, then all VMs perform equally. From a shares perspective, this is understandable because all VMs now have 500 shares.
I am having a hard time wrapping my head around the fact that VMware has allowed this seemingly poor design carry on for so many versions. Rather than specifying the total amount of CPU shares for a Resource Pool, you should be specifying how many shares per vCPU within the RP. The root RP appears to give 1000 shares per vCPU. So if you wanted to create a RP with lower CPU priority, the RP should have something like the result of 800 shares * #vCPU’s. For example: with 3 vCPU’s, the RP would have 2400 shares. If you added another vCPU, then the RP would need to have 3200. With the current implementation, this is a manual administrative task.
So, am I missing something? If not, then I believe Resource Pools and vApps should NOT be used, unless you are willing to manually manage the shares whenever the vCPU count changes.
By the way, I suspect memory shares will need to be managed in a similar fashion, but I have not tested to verify this.
You are correct, you didn’t miss a thing. Unfortunately current shares cannot be ignored and as such when RPs are being used they will always need to be manually calculated to avoid the RP Pie Paradox.
We would like to use RPs for management and reporting purposes in a private cloud deployment. The pie paradox makes me wonder if RPs can realistically be used. As a practice, we do not want to perform any type of QOS on resources with shares or otherwise. It would be ideal if there was a way to disable shares at that level. Since it is not, would one way to solve the problem be to use some automated process with the SDK to update shares assigned to resource pools based on query results from the number of VMs and some logic?
For instance it shouldn’t be very difficult to write a script that runs as part of a deployment workflow or daily maintenance that calculates the contents of the RP and sets shares based on some simple computations.
-Query RP Contents (# VMs, Allocated vRAM, Allocated vCPU)
-Assign X number of shares per YZW
-Modify RP attributes
As a designer i want to tell you that you have a very nice website , I enjoy the style and design, it really stands out.
I’ve found the best way around this is by creating a limit to the number of shares that are distributed in the “Resources” resource pool. We came up with a limit of 10,000 shares to be distributed, as this made for easy math.
In our production environment, we use the HIGH, NORMAL, and LOW resource pools. When I first started, we were running with a “Worst Case Allocation” on our Normal VMs that was 3x the WCA on our Low VMs. I had an idea for a script that would measure the total provisioned resources for each RP and assign a relative portion of the 10,000 based on that percentage — relative to the High, Normal, and Low nature.
So, I went to work and developed what we call our “Share Optimization Script”.
Quick summary:
1. Find the percentages of Total Provisioned Resources in the cluster that for all three RPs. (the script measures CPU and Mem in the same fashion and sets shares separately)
2. Starting with the High Resource Pool, multiply the percentage by 10,000, then by 1.2 (giving the High RP a 20% priority-per-resource over the other RPs). Set the RP to Custom and assign the shares.
3. Subtract the resultant High RP shares from 10,000 to find the remainder.
4. If the Normal percentage is less than the remainder, multiply the Normal percentage by 10,000, set the RP to Custom and assign the shares. Then, subtract the Normal from the remainder and assign the Low RP whatever is left.
5. If the Normal percentage is higher than the remainder, divvy up the remainder 80/20 between Normal/Low, respectively.
Here’s a real-life example of one of our clusters:
ResourcePool vCPUs MemoryMB vCPU% MEM% CPUShares MEMShares
High 106 306176 36.43 31.60 4371 3792
Normal 183 654500 62.89 67.55 6289 6755
Low 2 8276 .69 .85 1126 1242
In this case, there is enough of a remainder after High is provisioned that Normal can have all of what it needs. Note that the percentage multiplied by 10,000 makes for nice, neat numbers. The Low RP has more than it needs to run the two 1vCPU VMs inside, but the other two RPs have exactly what we want them to have.
Here’s another one of our clusters where the Normal gets its share, but the Low RP has to settle for the left overs:
ResourcePool vCPUs MemoryMB vCPU% MEM% CPUShares MEMShares
High 80 208600 10.06 9.81 1208 1177
Normal 657 351224 82.64 73.68 8264 7368
Low 58 351224 7.30 16.51 365 826
This is the first time I’ve publicly voiced the intentions of this script, and I’d like to get your input on it, if you don’t mind.
Thank you.
Sorry, to correct the first chart above (I was manually typing them in and mis-typed).
This example shows the 80/20 divvying up between Normal/Low when the High RP takes a substantial portion of the resources.
ResourcePool vCPUs MemoryMB vCPU% MEM% CPUShares MEMShares
High 106 306176 36.43 31.60 4371 3792
Normal 183 654500 62.89 67.55 4503 4967
Low 2 8276 .69 .85 1126 1242
In my testing I’m not seeing the same problem as others have posted. Instead of using shares I use reservations and they do not seem to be impacted shares like others have noted.
I am running a test with cpubusy.vbs on all the VM’s mentioned in the test to run the single vCPU machines at 100% CPU.
Test 1:
RP0 – 3600 MHZ Limit, 3600 MHZ Reserve <-This is to cause resource contention
RP1 – No limit shares at 1000
VM1 Capable of 2400
VM2 Capable of 2400
RP2 – No limit shares at 1000
VM3 Capable of 2400
Test 1 result: VM1&VM2 get 900 MHZ each and VM3 gets 1800. Not sure why the total does not equal 3600 Mhz but it does split everything out evenly as expected
Test 2:
RP0 – 3600 MHZ Limit, 3600 MHZ Reserve
RP1 – No limit shares at 1000, 2400 Mhz reserve
VM1 Capable of 2400
VM2 Capable of 2400
RP2 – No limit shares at 1000, 1200 Mhz reserve
VM3 Capable of 2400
Test 2 result: VM1 & VM2 get 1200 Mhz each and VM3 uses 1200 Mhz. Even despite share difference per VM.
Test 3:
RP0 – 3600 MHZ Limit, 3600 MHZ Reserve
RP1 – No limit shares at 1000, 2400 Mhz reserve
VM1 Capable of 2400
VM2 Capable of 2400
RP2 – No limit shares at 10000, 1200 Mhz reserve
VM3 Capable of 2400
Test 3 result: VM1 & VM2 get 1200 Mhz each and VM3 uses 1200 Mhz. Even distribution despite VM3 having 20x the shares of VM1 & VM2.
Am I missing something? Why bother with shares when reservations work well regardless of how many VM's live in a resource pool?
Frank wrote an excellent article about the impact of resource pool reservations:
http://frankdenneman.nl/2010/05/resource-pools-memory-reservations/
I would suggest reading it, but the “problem” with it is that you can only “reserve” it once. So if you have 400GB you can reserve 400Gb in total an anything that is required above the 400Gb will still be assigned based on the set shares. So even if you reserve and “overcommit” you could have these problems
The point I’m trying to make is that with proper reservations which avoid resource contention this becomes an issue that would be unlikely to hit and modifying resource shares like others are doing seems like a lot of work although very affective.
What I tend to do to mitigate this issue, but not solve it, is to pick reservations that lead to little or no contention.
It’s interesting that vCloud does not take into account shares when it builds out resources. So if you have 10 allocation pools with lets say a 50% reserve on memory and CPU the customer with the fewest VM’s will win the most memory and CPU in situation where contention exists. What would you recommend a cloud provider do outside of making sure resource contention never can happen and at that point why not just reserve 100%?
If you are not planning to overcommit why would you worry about it at all? If you are not overcommitting than shares are never a problem right. Shares comes in to play when there is resource contention.