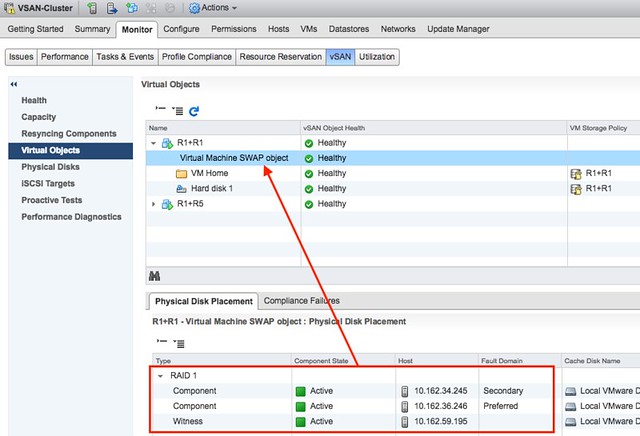
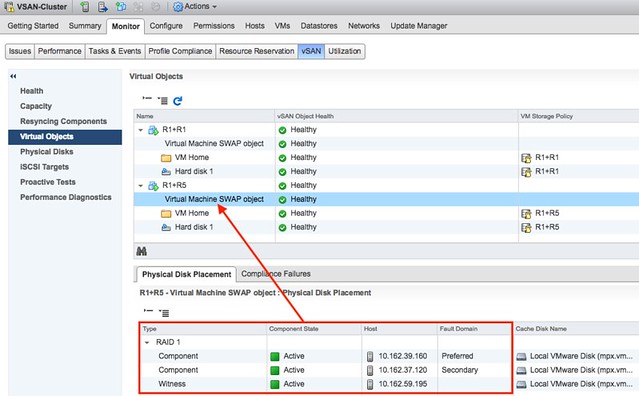
I had many requests for an updated version of this paper, so the past couple of weeks I have been working hard. The paper was outdated as it was last updated around the vSphere 6.0 timeframe, and it was only a minor update. I looked at every single section and added in new statements and guidance around vSphere HA Restart Priority for instance. So for those running a vSphere Metro Storage Cluster / Stretched Cluster of some kind, please read the brand new vSphere Metro Storage Cluster Recommended Practices (6.5 update) white paper.
It is available on storagehub.vmware.com in PDF and for reading within your browser. Any questions and comments, please do not hesitate to leave them here.
- vSphere Metro Storage Cluster Recommended Practices online
- vSphere Metro Storage Cluster Recommended Practices PDF