This week Site Recovery Manager 6.1 was announced. There are many enhancements in SRM 6.1 like the integration with NSX for instance and policy driven protection, but personally I feel that support for stretched storage is huge. When I say stretched storage I am referring to solutions like EMC VPLEX, Hitachi Virtual Storage Platform and IBM San Volume Controller(etc). In the past, and you can still today, when you had these solutions deployed you would have a single vCenter Server with a single cluster and moved VMs around manually when needed, or let HA take care of restarts in failure scenarios.
As of SRM 6.1 running these types of stretched configurations is now also supported. So how does that work, what does it allow you to do, and what does it look like? Well in contrary to a vSphere Metro Storage Cluster solution with SRM 6.1 you will be using two vCenter Server instances. These two vCenter Server instances will have an SRM server attached to it which will use a storage replication adaptor to communicate to the array.
But why would you want this? Why not just stretch the compute cluster also? Many have deployed these stretched configurations for disaster avoidance purposes. The problem is however that there is no form of orchestration whatsoever. This means that all workloads will come up typically in a random fashion. In some cases the application knows how to recover from situations like that, in most cases it does not… Leaving you with a lot of work, as after a failure you will now need to restart services, or VMs, in the right order. This is where SRM comes in, this is the strength of SRM, orchestration.
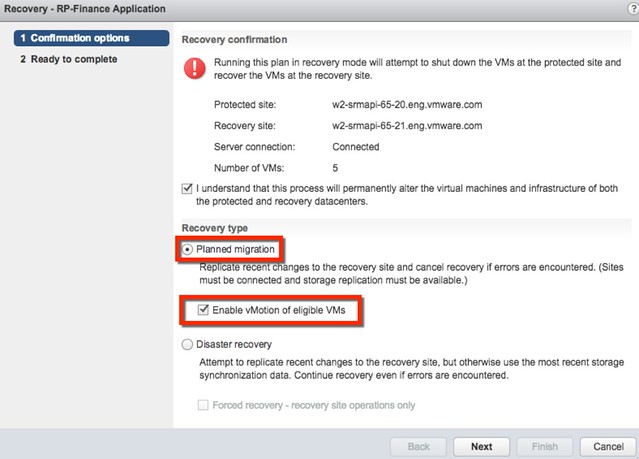
Besides doing orchestration of a full failover, what SRM can also do in the 6.1 release is evacuate a datacenter using vMotion in an orchestrated / automated way. If there is a disaster about to happen, you can now use the SRM interface to move virtual machines from one datacenter to another, with just a couple of clicks, planned migration is what it is called as can be seen in the screenshot above.
Personally I think this is a great step forward for stretched storage and SRM, very excited about this release!