Today during the Polish VMUG we had a great question, basically, the question was if you can vMotion a VM while vSAN IO Insight is tracing it. I did not know the answer as I had never tried it, so I had to test and validate it in the lab. While testing it became obvious that IO Insight and vMotion are not a supported combination today. Or better said, when you vMotion a VM which has IO Insight enabled and the VM is being traced, then the tracing will stop and you will not be able to inspect the results. When you click on view results you will see the error suggesting that the “monitored VMs might be deleted” as shown below.
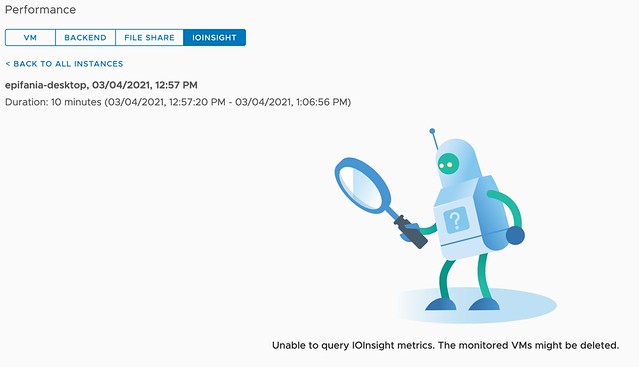
For now, if you are tracing a VM for an extended period of time, make sure to override the DRS automation level for that VM so that DRS does not interfere with the tracing. (You can do this on a per VM basis.) I would also recommend informing other administrators to not manually migrate the VM temporarily to avoid the situation where the trace is stopped. You may wonder why this is the case, well it is pretty simple, tracing happens on a host level. We start a user world on the host where the VM is running to trace the IO. If you move the VM, the user world doesn’t know what has happened to the VM unfortunately. For now, who knows if this is something that may change over time… Either way, I would always recommend not migrating VMs while tracing, as that also impacts the data.
Hope that helps, and thank Tomasz for the great question!

 If you haven’t seen it yet, you can pick up the
If you haven’t seen it yet, you can pick up the