Something that came up a couple of days back was a question around how VMware EVO:RAIL fits the ROBO (remote office branch office) use case. If you watched the demo you will have seen that it is very simple / easy to configure. It takes about 15 minutes to get you up and running and all you need to do is provide details like “IP ranges”, “Subnet mask”, “Gateway” and a couple of other globals.
This by itself makes EVO:RAIL a perfect solution for ROBO deployments… but there is more. When it comes to ROBO deployments and simplifying the roll out there are two more options:
- Provide configuration details during procurement process
- Specify configuration details in a file and insert in to appliance before shipment to remote office
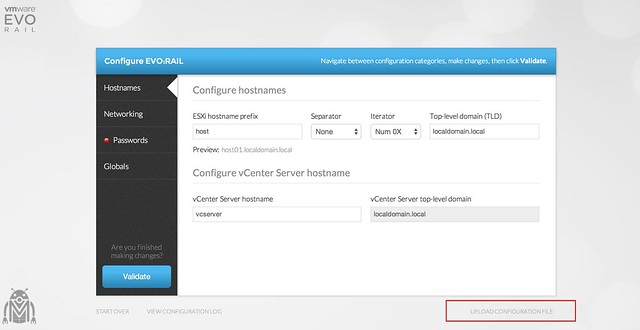
I won’t discuss option 1 in-depth, as this will very much depend on how each of the EVO:RAIL Qualified Partners handles this on their website / during the procurement process. Basically what happens is that you provide your preferred server vendor with configuration details and they put it in to a file called “default-config-static.json” and this is injected in to the vCenter Server Appliance which also runs the EVO:RAIL engine. For the hackers who want to play around with EVO:RAIL, note that the location of the json file and the format may change with newer versions so make sure to always use the latest and greatest if you want to play around. If you have filled out these details, you can just click
Option 2 is also very interesting if you ask me. If you look at EVO:RAIL as it stands today, you have the option to upload a JSON file when you hit the configuration screen (as shown in the screenshot above). This JSON should contain all of your configuration details and then will allow you to configure EVO:RAIL with the click of a button. In other words, you ship the appliance to your remote office. You email them the JSON file (in a secured manner hopefully) and ask them to click “upload configuration file”. They upload the file and then run “Validate”, and probably fill out the password as you don’t want to sent that in clear text. That is it… Nice right :). Of course, if you want … you could even go as far as injecting the .json file into the vCenter Server Appliance yourself, but I am not sure if that will be supported.
As you can imagine, this greatly simplifies the deployment of EVO:RAIL as all it takes is just one click to configure, which is ideal for a ROBO scenario. Anyone can do it!