I met with Runecast a couple of years ago at VMworld. Actually, I am not sure they already had a name back then, I should probably say I met with the guys who ended up founding Runecast at VMworld. One of them, Stan, is a VCDX and back then he pitched this idea to me around an appliance that would analyze your environment based on a set of KBs. His idea was primarily based on his experience managing and building datacenters. (Not just Stan’s experience, but most of the team are actually former IBM employees) Interesting concept, kind of sounded similar to CloudPhysics to me, although the focus was more on correlation of KB then capacity management etc.
Fast forward to 2017 and I just finished a call with the Runecast team. I had a short conversation at VMworld 2016 and was under the impression that they sold the company or quit. None of this is true. Runecast managed to get a 1.6m euro funding (Czech Republic) and is going full steam ahead. With around 10 people, most being in Czech Republic they are ready to release the next version of Runecast Analyzer, which will be 1.5. So what does this provide?
Well just imagine you manage a bunch of hosts and vCenter (not unlikely when you visit my blog), maybe some shared storage along with it. There are many KB articles, frequent updates of these and many newly published KBs every week. Then there’s also a whole bunch of best practices and of course the vSphere Hardening Guide. As an administrator do you have time to read everything that is published every day? And then when you have read it, do you have time to check your environment if the issue or best practice described applies to your infrastructure? Of course you don’t, and this is where Runecast Analyzer comes in to play.
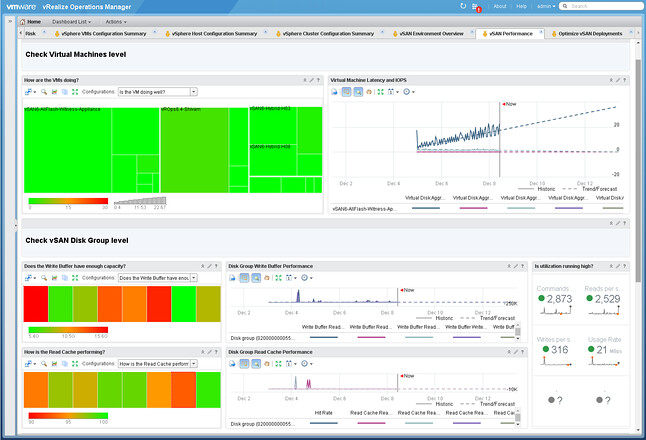
You download the appliance and provision it in to your environment, next you simply hook vCenter Server in to it and off you go. (As of 1.5 it also supports connecting several vCenter Server instances by the way.) Click analyze now and check the issues called out in the HTML-5 dashboard. As the screenshot below shows, this particular environment has issues identified in the log file that are described in a KB article. There are various other KB articles that may apply, just as an example: a combination of a certain virtual NIC with a specific OS may not be recommended. Also, various potential security issues and best practices are raised if they exist/apply.
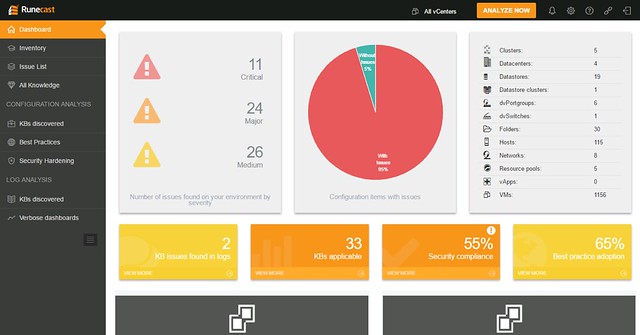
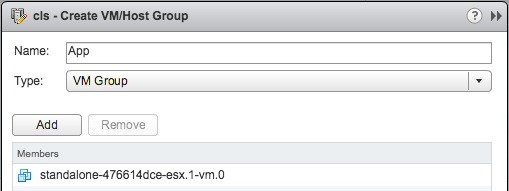
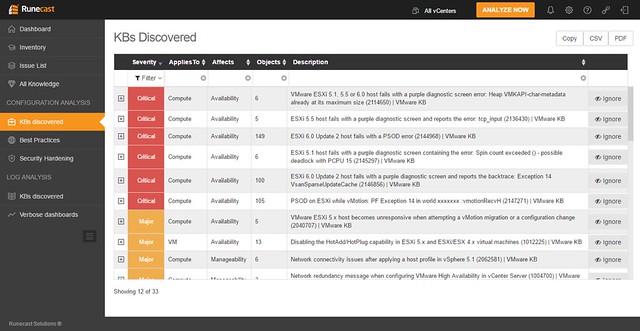
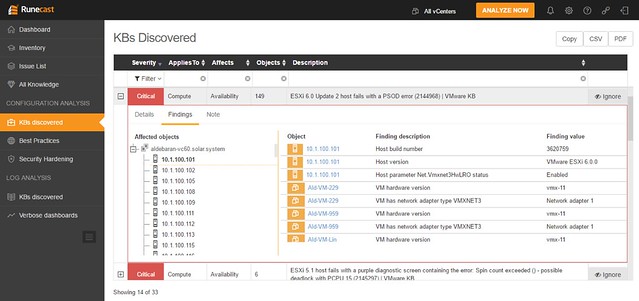
When you would click one of these areas you can drill down in to what the issue is and potentially figure out how to mitigate it. In the screenshot below you see the list of KBs that apply to this particular environment, you can open the particular entry (second screenshot below) and then find out to what it applies (objects: VMs, hosts, vCenter etc). If you feel it doesn’t apply to you, or you accept the risk, you can of course “ignore” the issue. When you click ignore a filter will be created which rules out this issue from being called out through the dashboard. The filtering mechanism is pretty smart, and you can easily create your own filters on any level of the virtual infra hierarchy. Yes, it is also possible to delete the filter(s) again when you feel it does apply to your environment.
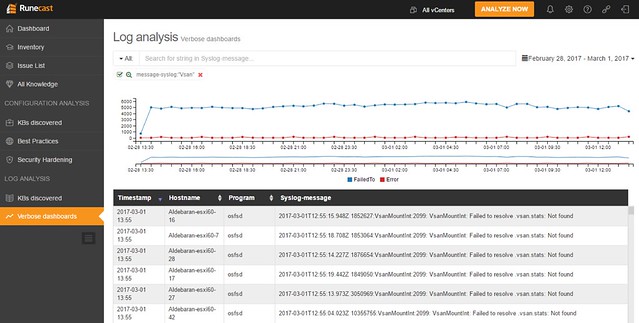
Besides checking the environment, as mentioned, Runecast can also analyze the logs for you. And I was happy to see that this got added, as it makes it unique compared to other solutions out there. Depending on what you are looking for you have these quick filtering options, and of course there are search strings and you can select a time period in which you would like to search of this particular string
As I said, all of this comes as a virtual appliance, which does not require direct connection to the internet. However, in order to keep the solution relevant you will need to update regularly, they mentioned they release a new data set once every two weeks roughly. It can be updated over the internet (through a proxy if needed), or you can download the ISO and update Runecast Analyzer through that, which could be very useful in secure locations. The appliance works against vSphere 5.x and 6.x (yes including 6.5) and there is a 30 day free trial. (Annual subscription, per socket pricing.) If you like to give it a try, click the banner on the right side, or go to their website: https://www.runecast.biz/. Pretty neat solution, and looking forward seeing what these guys can achieve with the funding they just received.