In episode 033 we spoke with Nabil Quadri about the Ransomware Recovery as a Service solution that VMware recently announced. Nabil discusses how common ransomware attacks are these days, and how customers are struggling to recover from them. He then goes on to explain how VMware Ransomware Recovery is built on the foundation of VMware Cloud Disaster Recovery, and he goes over the details of the offering and implementation. Listen now: Spotify (spoti.fi/3PkTTV7), Apple (apple.co/3UQvXdE), or simply use the embedded player below!
BC-DR
VMware announces Ransomware Recovery as a Service and Data Protection vision!
At VMware Explore there was a whole session (CEIB1236US) dedicated to the vision for Data Protection and Ransomware Recovery as a Service. Especially the Ransomware Recovery as a Service had my interest as it is something that keeps coming up with customers. How do I protect my data, and when needed how do recover? Probably a year ago or so I had a conversation with VMware CTO for Cloud Storage and Data (Sazzala) on this topic, and we met up with various customers to gather requirements. Those discussions ultimately led to the roadmap for this new service and new features. Below I am going to summarize what was discussed in this session at VMware Explore, but I would urge you to watch the session as it is very valuable, and it is impossible for me to capture everything.
VMware’s Disaster Recovery as a Service solution is a unique offering as it provides the best of both worlds when it comes to Disaster Recovery. With DR you typically have two options:
- Fast recovery, relatively high cost.
- Traditionally most customers went for this option, they had a “hot standby” environment that provided full capacity in case of emergency. But as this environment is always up and running and underutilized, it is a significant overhead.
- Slower recovery, relatively low cost.
- This is where VMs are replicated to cheap and deep storage and compute resources are limited (if available at all). When a recovery needs to happen, data rehydration is required and as such, it is a relatively slow process.
With VMware’s offering, you now have a 3rd option: Fast recovery, at a relatively low cost! VMware provides the ability to store backups on cheap storage, and then recover (without hydration) directly in a cloud-based SDDC. It provides a lot of flexibility, as you can have a minimum set of hosts constantly running within your prepared SDDC, and scale out when needed during a failure, or you can even create a full SDDC at the time of recovery.

Now, this offering is available in VMware Cloud on AWS in various regions. During the session, the intention was also shared to deliver similar capabilities on Azure VMware Solution, Oracle Cloud VMware Solution, Google Cloud VMware Engine, and/or Alibaba Cloud VMware Service. Basically all global hyper-scalers. Maybe even more important, VMware also discussed additional capabilities that are being worked on. Scaling to tens of thousands of VMs, managing multi-petabytes of storage, providing 1-minute RPO levels, proving multi-VM consistency, having end-to-end SLA observability, providing advanced insights into cost and usage, and probably most important… a full REST API.
All of those enhancements are very useful for those aiming to recover from a disaster, not just natural disasters, but also for Ransomware attacks. Some of you may wonder how common a ransomware attack is, but unfortunately, it is very common. Surveys have revealed that 60% of the surveyed organizations were hit by ransomware in the past 12 months, 92% of those who paid the ransom did not gain full access to the data, and the average downtime was 16 days. Those are some scary numbers in my opinion. Especially the downtime associated with an attack, and the fact that full access was not regained even after paying a ransom.
In general recovery from ransomware is complex as ransomware typically remains undetected for larger periods of time before you are exposed to it. Then when you are exposed you don’t have too many options, you recover to a healthy point in time or you pay the ransom. When you recover, of course, you want to know if the set you are recovering is infected or not. You also want to have some indication of when the environment was infected, as no one wants to go through 3 months of snapshots before you find the right one. That alone would take days, if not weeks, and downtime is extremely expensive. This is where VMware Ransomware Recovery for VMware Cloud DR comes in.
The aim for the VMware Ransomware Recovery for VMware Cloud DR solution is to provide the ability to recover to an Isolated Recovery Environment (including networking). This first of all prevents reinfection at the time of recovery. During the recovery process, the environment is also analyzed by a next-generation anti-virus scanner for known/current threats. Simply to prevent a situation where you recover a snapshot that was infected. What I am even more impressed by is that the plan is to also include a visual indication of when most likely an environment was infected, this is done by providing an insight into the data change rate and entropy. Now, entropy is not a word most non-native speakers are familiar with, I wasn’t, but it refers to the randomness of the data. Both the change rate and the entropy could indicate abnormal patterns, which then could indicate the time of infection and help identify a healthy snapshot to recover!

As mentioned, during recovery the snapshot is scanned by a Next-Gen AV, and of course, when infections are detected they will be reported in the UI. This then provides you the option to discard the recovery and select a different snapshot. Even if no vulnerabilities are found the environment can be powered on fully isolated, providing you the ability to manually inspect before exposing app owners, or end-users, to the environment again.
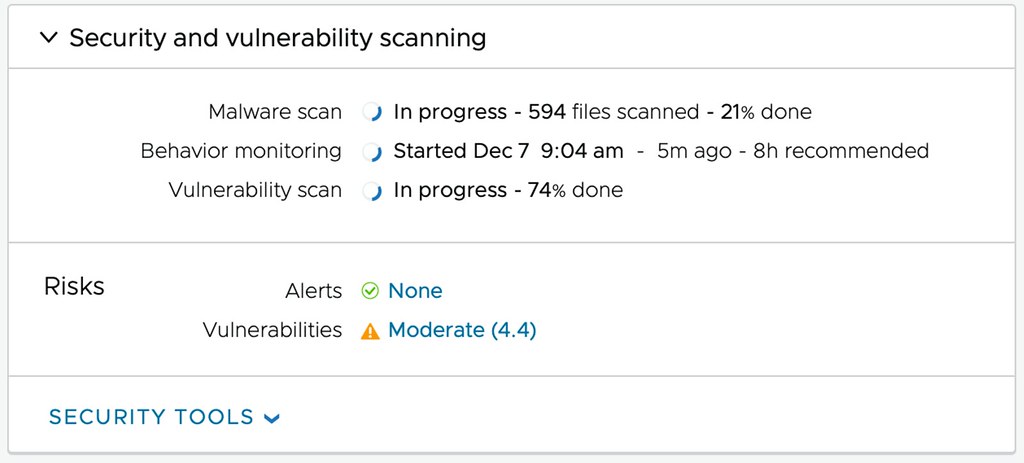

Now comes the cool part, when you have curated the environment, when you are absolutely sure this is a healthy point in time that was not infected, you have the choice to fallback to your “source” environment or simply remain running in your VMware Cloud while you clean up your “source” site. Before I forget, I’ve been talking about full environments and VMs so far, but of course, it is also the intention to provide the ability to restore files and folders of course! All in all, a very impressive solution that should be available in the near future.
If you are interested in these capabilities and would like to stay informed, please fill out this form: https://forms.office.com/r/yh69Npq7nY.
Nested Fault Domains on a 2-Node vSAN Stretched Cluster, is it supported?
I spotted a question this week on VMTN, the question was fairly basic, are nested fault domains supported on a 2-node vSAN Stretched Cluster? It sounds basic, but unfortunately, it is not documented anywhere, probably because stretched 2-node configurations are not very common. For those who don’t know, with a nested fault domain on a two-node cluster you basically provide an additional layer of resiliency by replicating an object within a host as well. A VM Storage Policy for a configuration like that will look as follows.

This however does mean that you would need to have a minimum of 3 fault domains within your host as well if you want to, this means that you will need to have a minimum of 3 disk groups in each of the two hosts as well. Or better said, when you configure Host Mirroring and then select the second option failures to tolerate the following list will show you the number of disk groups per host you need at a minimum:
- Host Mirroring – 2 Node Cluster
- No Data Redundancy – 1 disk group
- 1 Failure – RAID1 – 3 disk groups
- 1 Failure – RAID5 – 4 disk groups
- 2 Failures – RAID1 – 5 disk groups
- 2 Failures – RAID6 – 6 disk groups
- 3 Failures – RAID1 – 7 disk groups
If you look at the list, you can imagine that if you need additional resiliency it will definitely come at a cost. But anyway, back to the question, is it supported when your 2-node configuration happens to be stretched across locations, and the answer is yes, VMware supports this.
Unexplored Territory: recovering from a ransomware attack /w Sazzala Reddy!

There we go, episode 002 of the Unexplored Territory Podcast was just published. In this episode we talk to Sazzala Reddy. Sazzala is a Chief Technologist at VMware who joined via the Datrium acquisition, where he was the CTO. Before founding Datrium, he was at Dell/EMC, where he came in via the DataDomain acquisition. I think it is fair to say that Sazzala has a heavy data/storage DNA. We discuss Sazzala’s career path, why better is sometimes worse, and we extensively discuss VCDR and the new cloud file system that is being developed. I think it is a very interesting episode and would encourage everyone to give it a listen!
Make sure to follow Sazzala on twitter (https://twitter.com/sazzala) and read his blog post on the VCDR filesystem: https://bit.ly/3CiQoav.
Listen now via Apple Podcasts: https://apple.co/2ZOziDx, Spotify: https://spoti.fi/3BEkFja, Google: https://bit.ly/3Cy3ssF, Overcast: https://overcast.fm/+zyG9k_hks, Website: https://bit.ly/3w70FnV.
Can I make a host in a cluster the vSphere HA primary / master host?
There was an interesting question on the VMware VMTN Community this week, although I wrote about this in 2016 I figured I would do a short write-up again as the procedure changed since 7.0u1. The question was if it was possible to make a particular host in a cluster the vSphere HA primary (or master as it was called previously) host. The use case was pretty straightforward, in this case, the customer had a stretched cluster configuration with vSAN, they wanted to make sure that the vSphere HA primary host was located in the “preferred” site, as this could potentially speed up the restart of VMs. Now, mind you, that when I say “speed up” we are talking about 2-3 seconds difference at most, but for some folks, this may be crucial. I personally would not recommend making configuration changes, but if you do want to do this, vSphere does have the option to do so.
When it comes to vSphere HA, there’s no UI option or anything like that to assign the “primary/master” host role. However, there’s the option to specify an advanced setting on a host level to indicate that a certain host needs to be favored during the primary/master election. Again, this is not very common for customers to configure, but if you desire to do so, it is possible. The advanced setting is called “fdm.nodeGoodness” and depending on which version you use, you will need to configure it either via the fdm.cfg file, or via the configstorecli. You can read about this process in-depth here.
Of course, I did try if this worked in my lab, here’s what I did, I first list the current configured advanced options using configstorecli for vSphere HA:
configstorecli config current get -g cluster -c ha -k fdm
{
"mem_reservation_MB": 200,
"memory_checker_time_in_secs": 0
}
Next, I will set the “node_goodness” for my host, when setting this it will need to be a positive value, in my case I am setting it to 10000000. I first dumped the current config in a json file:
configstorecli config current get -g cluster -c ha -k fdm > test.json
Next, I edited the file and added the setting “node_goodness” with a value of 10000000, so that is looks as follows:
{
"mem_reservation_MB": 200,
"memory_checker_time_in_secs": 0,
"node_goodness": 10000000
}
I then imported the file:
configstorecli config current set -g cluster -c ha -k fdm -infile test.json
After importing the file and reconfiguring for HA on one of my hosts, you can see in the screenshots below that the master role moved from 1507 to 1505.


I also created a quick demo, for those who prefer video content: