I was digging through my blog for a link to a vVols primer article and I realized I never wrote one. I did an article which described what Virtual Volumes (VVol) is in 2012 but that is it. I am certain that Virtual Volumes is a feature that will be heavily used with vSphere 6.0 and beyond, so it was time to write a primer. What is vVols about? What will they bring to the table?
First and foremost, vVols was developed to make your life (vSphere admin) and that of the storage administrator easier. This is done by providing a framework that enables the vSphere administrator to assign policies to virtual machines or virtual disks. In these policies capabilities of the storage array can be defined. These capabilities can be things like snapshotting, deduplication, raid-level, thin / thick provisioning etc. What is offered to the vSphere administrator is up to the Storage administrator, and of course up to what the storage system can offer to begin with. When a virtual machine is deployed and a policy is assigned then the storage system will enable certain functionality of the array based on what was specified in the policy. So no longer a need to assign capabilities to a LUN which holds many VMs, but rather a per VM or even per VMDK level control. So how does this work? Well lets take a look at an architectural diagram first.
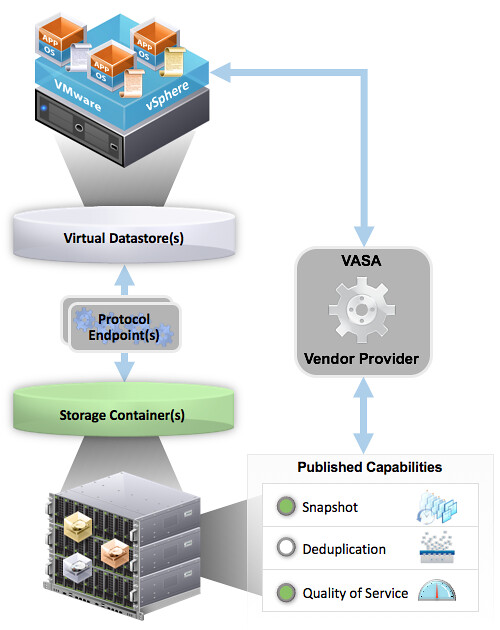
The diagram shows a couple of components which are important in the VVol architecture. Lets list them out:
- Protocol Endpoints aka PE
- Virtual Datastore and a Storage Container
- Vendor Provider / VASA
- Policies
- vVols
Lets take a look at all of these three in the above order. Protocol Endpoints, what are they?
Protocol Endpoints are literally the access point to your storage system. All IO to vVols is proxied through a Protocol Endpoint and you can have 1 or more of these per storage system, if your storage system supports having multiple of course. (Implementations of different vendors will vary.) PEs are compatible with different protocols (FC, FCoE, iSCSI, NFS) and if you ask me that whole discussion with vVols will come to an end. You could see a Protocol Endpoint as a “mount point” or a device, and yes they will count towards your maximum number of devices per host (256). (Virtual Volumes it self won’t count towards that!)
Next up is the Storage Container. This is the place where you store your virtual machines, or better said where your vVols end up. The Storage Container is a storage system logical construct and is represented within vSphere as a “virtual datastore”. You need 1 per storage system, but you can have many when desired. To this Storage Container you can apply capabilities. So if you like your virtual volumes to be able to use array based snapshots then the storage administrator will need to assign that capability to the storage container. Note that a storage administrator can grow a storage container without even informing you. A storage container isn’t formatted with VMFS or anything like that, so you don’t need to increase the volume in order to use the space.
But how does vSphere know which container is capable of doing what? In order to discover a storage container and its capabilities we need to be able to talk to the storage system first. This is done through the vSphere APIs for Storage Awareness. You simply point vSphere to the Vendor Provider and the vendor provider will report to vSphere what’s available, this includes both the storage containers as well as the capabilities they possess. Note that a single Vendor Provider can be managing multiple storage systems which in its turn can have multiple storage containers with many capabilities. These vendor providers can also come in different flavours, for some storage systems it is part of their software but for others it will come as a virtual appliance that sits on top of vSphere.
Now that vSphere knows which systems there are, what containers are available with which capabilities you can start creating policies. These policies can be a combination of capabilities and will ultimately be assigned to virtual machines or virtual disks even. You can imagine that in some cases you would like Quality of Service enabled to ensure performance for a VM while in other cases it isn’t as relevant but you need to have a snapshot every hour. All of this is enabled through these policies. No longer will you be maintaining that spreadsheet with all your LUNs and which data service were enabled and what not, no you simply assign a policy. (Yes, a proper naming scheme will be helpful when defining policies.) When requirements change for a VM you don’t move the VM around, no you change the policy and the storage system will do what is required in order to make the VM (and its disks) compliant again with the policy. Not the VM really, but the vVols.
The great thing about vVols is the fact that you know have a granular control over your workloads. Some storage systems will even allow you to assign IO profiles to your VM to ensure optimal performance. Also, when you delete a VM the vVols will be deleted and the space will automatically be reclaimed by the storage system, no more fiddling with vmkfstools. Another great thing about virtual volumes is that even when you delete something within your VM this space can also be reclaimed by the storage system. When your storage system supports T10 UNMAP that is.
That is in short how vVols work and what they bring. You as the vSphere administrator create policies and assign those to VMs, while the storage administrator manages capacity and capabilities. Easy right?!
As far as the protocol endpoints are concerned do you still setup your normal iSCSI or FC initiators to discover these like volumes and luns? Or is it a different initiator of sorts to find the PE’s in the storage subsystem via iSCSI and FC?
You setup your initiators the exact same way.
As an administrator, it sounds like I still need to mount the datastores and do all that busy work. Then I have to go through the additional steps to configure the containers. Can you help me understand how this is a benefit to me as the administrator?
I do not have issues picking a datastore. I know every datastore’s performance capabilities as I name them in relation to their performance. I also know how everything is backed up.
Is the benefit of this for those that are not admins and simply end users that need to pick a performance tier and array-based backup method without any critical thinking?
I will admit I don’t completely understand VVols, but this primer has helped.
First of all you are making the assumption everything is owned/managed by the same person which is simply not the case for many companies.
Secondly, you are doing things at a LUN level now and need to move workloads around as requirements change, with VVols you change the policy or select a new policy, the rest will happen for you.
In todays world you create new LUNs when they fill up here you increase the size of the container. That is 1 action versus many you have to take today.
And we are not just talking performance, there are many more things that can be exposed, all the way up to application performance profiles if your array supports this.
Hi Mike,
VVOLs allow you to get away from creating LUNs, formatting LUNs, mounting Datastores, etc.. You create a Storage Container of (X) capacity on a storage device. (or part of it, e.g. pools on EQL storage). When you create a VM, it will create three volumes in the selected container. One VMX config, one for VMware swap and the boot volume. You then load the OS onto that VM using its native filesystem. So you reduce the I/O overheard and shared LUN issues. If you add another virtual disk you get another volume inside a container. Doesn’t have to be the same container. So if you have SAS and SSD based containers you can leverage those. You can grow of shrink the Storage Container at any time. So need to grow or shrink a filesystem.
There are many advantages to VVOLs. Plus the array and ESXi share more info about what’s going on with the storage.
Regards,
Don
The protocol endpoint bit confuses me. Is this just a storage processor? Or will VM traffic be proxied through some VM now??
For NFS, the PE is simply an NFS mount point, and the virtual disks are files beneath that mount point. For SAN protocols, the PE is a proxy LUN. vSphere supports only 256 direct LUN connections per ESXi host; the proxy LUN acts as a multiplexor, allowing each ESXi host to address thousands of underlying LUNs, each with a unique identifier. Each LUN corresponds to a virtual disk.
Is there any support for clustered devices (e.g. for MSCS or Oracle ASM disks)?
Honestly speaking I cant see the benefit too.
Right now storage team will provision you several thin volumes on the storage system (maybe with different capabilities like QoS, dedup etc.) There is no penalty on thin volumes in terms of storage array so you dont need to create “storage space” as a VMware admin “on the fly”
Then you create few storage clusters with those volumes (aggain with different capabilites) and then you provision VMs.
What benefit is if you create the VM on the stroge directly and eliminates the SAN team? The only benefity I see right now (but on the other side it will complicated the SAN point of view) is that you have LUN per VM (if I understand it well) which may be interesting for a bacup solution (replication on the array level insted of VMware level which will be quite faster)
Benefits?
Proper policy based management with:
– QoS on a per disk level
– Data services (snapshots, and replication soon and anything else) on a per disk level definable
– No need to SvMotion disks / VMs around when requirements change
– Little to no chance to hit that 256 Device limit
– IO characterisation (if your array supports this, like Nimble for instance)
– Array native snapshot usage
– No more hitting the 256 device limit
– etc.etc.etc.
But again, this may not be for everyone. Some may not think there is any benefit for them and keep running in the traditional way, either will work fine.
Great read, thanks.
Had a bunch of questions but found a good Q&A which answered them all.
Q24, Q27 and Q28 answered my questions about the VMX, VDMK vs Flat and Snapshots.
http://www.vmware.com/files/pdf/products/virtualvolumes/VMware_Virtual_Volumes_FAQ.pdf
Thanks to @PunchingClouds for the FAQ PDF
I think people might be missing the point about VVOLS for now. It took me a little bit to fully understand, but it’s a huge shift in how storage is used in vSphere. Think of it like every virtual disk is like a physical mode RDM – without the associated overhead. You get the full capabilities of the storage array. When you take a snapshot in vCenter, it’s the array doing the snap. When you perform a clone in vCenter, it’s your storage array that is doing the clone. Capabilities that you need VAAI for today, you get natively via VVOLS (although VAAI will still co-exist). Today, depending on the storage protocol (NFS, iSCSI, FC) you need storage vendor plug-ins to support VAAI (i.e. VAAI NFS). With VVOLS you don’t. I think once peole start to use VVOLS, they’ll see the big difference.
Yeah, VVOL is interesting.. But its unique to VMware. And its a really heavy lock-in thing. It takes a massive effort to design a VVOL setup properly, especially for service providers.
If you already run, or are looking at running Hyper-V and/or KVM, then VVOL won’t work for you.
Where I work we have multiple PB and thousands and thousands of VMs on VMware today. But its looking more and more like we’re moving to Hyper-V due to costs. And going to VVOL now would probably be just a lot of wasted time. I’m sure we’re not alone in this situation either.
This is where stuff like Tintri becomes quite interesting. It has a lot(if not most) of the advantages that VVOL has, but it offers it for Hyper-V and KVM as well.
Hi Duncan,
I think we desperately need a detailed whitepaper that covers the architecture and benefits.
My expectation, as you suggest above, was that you could change per VM policies on the fly like you can with VSAN, but this is not the case.
VASA is a read only technology that presents the characteristics of a volume and SBPM determines which volume to place a VM on. If you change the policy the VM needs to be moved – not ideal.
I posted more thoughts on this at http://cormachogan.com/2015/02/27/migrations-and-virtual-volumes-deep-dive/
VMware needs a major PR exercise to rescue VVOLs as currently it is not doing a good job of articulating why people should use it and therefore negativity is developing around it.
My gut feel is that the current version does not deliver on the intended vision of the technology and we will see a major update over the next year.
Cormac hints at this in his post above.
At the end of the day you need a storage array that can snap, replicate and dedupe, etc. at a VVOL level and there are very few that can do this.
I was certain that NetApp would be able to but when I looked into it I found out I was wrong – more at http://blog.snsltd.co.uk/a-deeper-look-into-netapps-support-for-vmware-virtual-volumes/
My assumption was that the reason for the delays in launching VVOLs was because the array vendors needed to re-architect their products to deliver per VVOL granular mangement but this does not appear to be the case.
Your thoughts would be much appreciated.
Best regards
Mark
VSAN 1.0 didn’t deliver the promises and benefits of VSAN 6.0. To expect VVOLS 1.0 to meet all of your expectations out of the gate, is a little presumptuous.
Not sure I understand your comments to be honest. I mean, depending on the type of data services you select and what the capabilities are of the array and the container the volume is stored, yes data may need to be moved indeed.
Note that VVOL is a framework, the implementation will differ from vendor to vendor. Not much I can change about that.