I have never made it a secret that I am a fan of Tintri. I just love their view on storage systems and the way they decided to solve specific problems. When I was in Palo Alto last month I had the opportunity to talk to the folks of Tintri again and what they were working on. Of course we had a discussion about the Software Defined Datacenter and more specifically Software Defined Storage and what Tintri would bring to the SDS era. As all of that was under strict NDA I can’t share it, but what I can share are some cool details of what Tintri has just announced, version 2.0 of their storage system.
For those who have never even looked in to Tintri I suggest you catch-up by reading the following two articles:
When I was briefed initially about Tintri back in 2011 one of the biggest areas of improvement I saw were around availability. Two things were on my list to be solved, first one was the “single controller” approach they took. This was solved back in 2011. Another feature I missed was replication. Replication is the main feature that is announced today and it will be part of the 2.0 release of their software. What I loved about Tintri is that all data services they offered were on a virtual machine level. Of course the same applies to replication, announced today.
Tintri offers a-synchronous replication which can go down to a recovery point objective (RPO) of 15 minutes. Of course I asked if there were plans on bringing this down, and indeed this is planned but I can’t say when. What I liked about this replication solution is that as data is deduplicated and compressed the amount of replication traffic is kept to a limit. Let me rephrase that, globally deduplicated… meaning that if a block already exists in the DR site then it will not be replicated to that site. This will definitely have a positive impact on your bandwidth consumption, and Tintri has seen up to 95% reduction in WAN bandwidth consumption. The diagram below shows how this works.
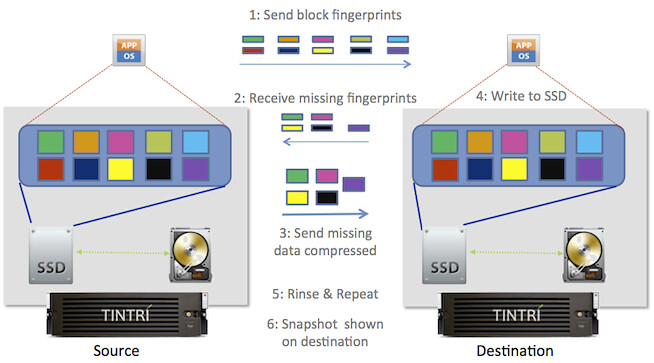
The nice thing about the replication technique Tintri offers is that it is well integrated with VMware vSphere and thus it offers “VM consistent” snapshots by leveraging VMware’s quiescing technology. My next obvious question was what about Site Recovery Manager? As failover is on a per VM basis, orchestrating / automating this would be a welcome option. Tintri is still working on this and hopes to add support for Site Recovery Manager soon. Another I would like to see added was grouping of virtual machines for replication consistency; again this is something which is on the road map and hopefully will be added soon.
One of the other cool features which is added with this release is remote cloning. Remote cloning basically allows you to clone a virtual machine / template to a different array. Those who have multiple vCenter Server instances in their environment know what a pain this can be, hence the reason I feel this is one of those neat little features which you will appreciate once you have used it. Would be great if this functionality could be integrated within the vSphere Web Client as a “right click”, judging by the comments made by the Tintri team I would expect that they are already working on deeper / tighter integration with the Web Client, and I can only hope a vSphere Web Client plugin will be released soon so that all granular VM level data services can be managed from a single console.
All-in-all a great new release by Tintri, if you ask me this release is 3 huge steps forward!