The state of vSphere clustering
By Irfan Ahmad
Some of my colleagues at CloudPhysics and I spent years at VMware and were lucky to have participated in one of the most rapid transformations in enterprise technology history. A big part of that is VMware’s suite of clustering features. I worked alongside Carl Waldspurger in the resource management team at VMware that brought to the world the ESX VMkernel CPU and memory schedulers, DRS, DPM, Storage I/O Control and Storage DRS among other features. As a result, I am especially interested in analyzing and improving how IT organizations use clustering.
Over a series of blog posts, I’ll try to provide a snapshot of how IT teams are operationalizing vSphere. One of my co-founders, Xiaojun Liu and I performed some initial analysis on the broad community dataset that is continually expanding as more virtualization engineers securely connect us to their systems.
First, we segmented our analysis based on customer size. The idea was to isolate the effect of various deployment sizes including test labs, SMBs, commercial and large enterprise, etc. Our segmentation was in terms of total VMs in customer deployments and divided up as: 1-50 VMs, 51-200, 201-500, 501-upwards. Please let us know if you believe an alternative segmentation would warrant better analysis.
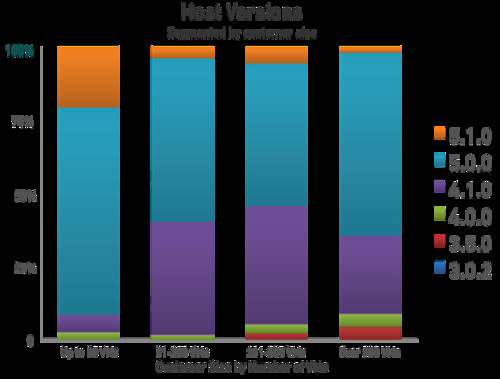
Initially we compared various ESX versions deployed in the field. We found ESXi 5.0 already captured the majority of installations in large deployments. However, 4.0 and 3.5 versions continue to be deployed in the field in small numbers. Version 4.1, on the other hand, continues to be more broadly deployed. If you are still using 4.1, 4.0, and 3.5, we recommend upgrading to 5.0 which provides greatly improved HA clustering, amongst many other benefits. This data shows the 5.0 version has been broadly adopted by our peers and is user-verified production ready.
Next, we looked at cluster sizes. A key question for VMware product managers was often, “How many hosts are there in a typical cluster?” This was a topic of considerable debate, and it is critically important to know when prioritizing features. For example, how much emphasis should go into scalability work for DRS.
For the first time, CloudPhysics is able to leverage real customer data to provide answers. The highest frequency cluster size is two hosts per cluster for customers with greater than 500 VMs. Refer to the histogram. This result is surprisingly low and we do not yet know all the contributing reasons, though we can speculate on some of the causes. These may be a combination of small trainiång clusters, dedicated clusters for some critical applications, Oracle clustering license restrictions, or perhaps a forgotten pair of older servers. Please tell us why you may have been keeping your clusters small.
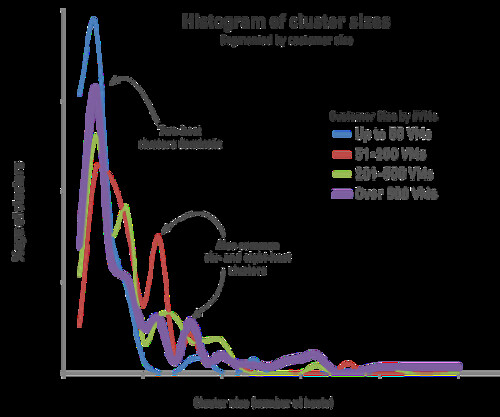
Despite the high frequency of two-host clusters, we see opportunities for virtualization architects to increase their resource pooling. By pooling together hosts into larger clusters, DRS can do a much better job at placement and providing resource management. That means real dollars in savings. It also allows for more efficient HA policy management since the absorption of spare capacity needed for infrequent host failures is now spread out over a larger set of hosts. Additionally, having fewer clusters makes for fewer management objects to configure, keep in sync with changing policies, etc. This reduces management complexity and makes for a safer and more optimized environment.
Several caveats arise with regard to the above findings. First is potential sample bias. For instance, it might be the case that companies using CloudPhysics are more likely to be early adopters and that early adopters might be more inclined to upgrade to ESX 5.0 faster. Another possible issue is imbalanced dataset composition. It might be that admins are setting up small training or beta labs, official test & development, and production environments mixed in the same environment thus skewing the findings.
CloudPhysics is the first to provide a method of impartially determining answers based on real customer data, in order to dampen the controversy.

Xiaojun and I will continue to report back on these topics as the data evolves. In the meantime, the CloudPhysics site is growing with new cards being added weekly. Each card solves daily problems that virtualization engineers have described to us in our Community Cards section. I hope you will take the time to send us your feedback on the CloudPhysics site.
Duncan,
Regarding 2-node clusters. Many customers (especially in bracket below 200VMs) do not need more than 2 hosts. Why would they if you can get hosts with 512GB or 1TB RAM (or possibly even more these days) in them? 99% of customers I am working with NEVER have an issue with CPU, it is always Storage or RAM.
Precisely why we segregate small environments from medium to large in our analysis.
You think customers who have 200 VMs will run those on 2 hosts with 1TB of memory? I think it is more likely they have 3 or 4 hosts at that stage to spread the risks / load. Also from a cost perspective it might even be less expensive to have 4 smaller hosts than 2 large ones.
Duncan, it’s my belief that most VI admins find resource pools intimidating and use smaller clusters to allocate resources to their application groups.
They all read the Priority Pie Paradox blog post on your site and gave up in favor of small clusters. 😉
Another reason for 2-Node clusters I’ve seen are “management clusters.” They keep a DC, vCenter and sometimes even a SQL box for vCenter or other VMware solutions.
Good point. We’ll see if we can segregate management clusters in our data to make the analysis cleaner.
At VMware, in Integration Engineering, we push management clusters of 4 hosts a lot. I am starting to see more customers with 3 host management clusters. But I think you at CloudPhysics may have people connecting lab gear to your world to see how you work, and if it is safe, and than they may bring the production clusters to you. I do not like 2 host clusters and would only use them in specific circumstances, generally in ROBO. So curious why you see so many.
Great write up and I look forward to more.
In larger organizations, I have seen several 2-node management clusters, with several 4-8 node resource clusters. This protects vCenter, DNS/DHCP, SQL server, and IT-administrative or monitoring VMs such as vCOps, Veeam, SolarWinds, etc. If each customer had a 2-node admin cluster, this would account for the large number.
Maybe the 2-node-clusters are systems with an older version of vSphere and the hosts and/or the VMs could not be upgraded to a newer version (for whatever reason). Are there bigger clusters (with newer versions) at the same site where you find the 2-node-clusters?
Marko,
Regarding version – it is actually other way around. Since whatever version vCenter is supported as running as VM, we have many customers 100% virtualized (Duncan – OK, maybe not 2 host clusters, but definitely no more than 3 hosts). Getting maximum possible memory into hosts was temporarily delayed by vRAM tax (was is justified or not – that is different question), but now they are coming back. Recent customer I upgraded to 5.1 was running 80+ VMs per 512GB hosts…
I try to keep mine under the vSphere Essential Plus umbrella so I started with a 2 node cluster but now I am up to 3. But I also have 4 other suite that are under 4 different vCenter so if I combine them all it is a 12 node cluster. One for Server Cluster, the second is VDI cluster and the 3rd and 4th are on an entirely different network that they are not allowed to talk amongst each other. Duncan hit the nail on the head “spreading the risk”, this is so important these days, the VDI group are not the same admins on the Server Admin group. Part of the reason as well is guess licensing compliance whether Oracle or Microsoft. It is cheaper to buy 4 Datacenter Windows 2008R2 for a 2 node cluster. But even the licensing issue is really difficult to enforce under the virtual world so I don’t make it a huge factor on my clustering plan. But like everyone said virtualization is so efficient that you constantly ask yourself if you can justify the need for a thrid host.
It will be also interesting to know what storage systems are they using with the two node cluster.
Maybe, in the CloudPhysics Portal, the admin can have an option to register a cluster as Lab or Production.
That’s a fabulous idea. Let me take this to the team. Question for you: would it be ok to ask about production/test-dev nature of your clusters as part of our usual workflows?
I wouldn’t mind especially when I can reply with “no comment” if it is sensitive information. And wasn’t that also part of CloudPhysics that you can tell if my environment is running fine or not compared to equal businesses?
In our NL site we have 13 hosts, that where previously devided into a group of 5 for Oracle, and 13 for Linux/Windows.
However, to cut Microsoft licensing costs, we have now created a dedicated 3-host Windows cluster. (6 datacenter licenses)
I did actually not agree with the approach of creating seperate clusters for this reason, as I suspect DRS affinity rules should be enough to ensure that certain OS’s remain on certain licensed physical hosts. But would Oracle/MS agree with me??
Our other locations have clusters of 6 and 2, again Linux/Windows vs Oracle.
Robert, I totally agree with your affinity rule logic. This Vmworld video is so appropriate to the licensing topic you mention as well. Licensing is a snapshot of time (normally during audit). If I have a 15 DL380 cluster and I only bought two Win2008R2 datacenter license to run 100 vm on one ESXi host and I know I am abiding by that rule then the “burden of proof” is on Microsoft (same with Oracle). Microsoft has the burden of proof and they need to prove me wrong (after some log purging). Virtualization is moving forward and licensing folks need to catch up. VDI licensing is another can of worm issue, I am not content with the VDA license answer .
forgot the video