I was reading Eric Siebert’s excellent article on Changed Block Tracking(CBT) and the article on Punching Cloud on this new feature which is part of vSphere. CBT enables incremental backups of full VMDKs. Something that isn’t covered is what the “block” part of Changed Block Tracking actually stands for.
Someone asked me on the VMTN Communities and it’s something I had not looked into yet. The question was around VMFS block sizes and the way it could potentially have its effect on the size of a backup which uses CBT. The assumption was made that CBT on a 1MB block size VMFS volume uses 1MB blocks and on an 8MB block size VMFS volume uses 8MB blocks. This is not the case.
So what’s the size of the block that CBT refers to? Good question I’ve asked around and the answer is that it’s not a specific size but it has a variable size. The block always starts with 64KB and the bigger the VMDK becomes the bigger the blocks become.
Just for the sake of it:
- CBT is on a per VMDK level and not on a VMFS level.
- CBT has variable block sizes which are dictated by the size of the VMDK.
- CBT is a feature that lives within the VMKernel and not within VMFS.
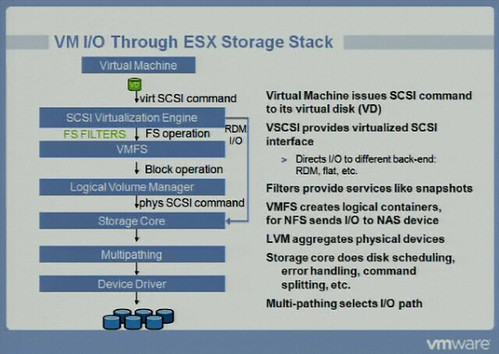
- CBT is a FS Filter as shown in the VMworld slide below
I was curious on this myself and never found a good answer. How does CBT handle sub-block allocation? Sub-blocks are 1/16 the size of a 1MB block (or 1/128 the size of an 8MB block), I assumed it created a CBT record for each sub-block in a VMDK file. Since the size of the CBT file is fixed no matter how much data changes I’m guessing it creates a record for each block in it when CBT is enabled and then just sets a bit on whether the block has been changed or not.
Informative as always. Thanks Duncan!
Does the VMDK block size have any effect on the de-duplication that Data Recovery performs?
@Eric – I think you are mixing up VMFS Blocks and CBT Blocks. VMFS can use sub-blocks this is something totally different and only used for small files.
@Brad no it doesn’t as the blocks used for CBT are different blocks than VMFS blocks.
Brad,
at least for our backup product: EMC Avamar, CBT makes a big big difference..
it’s a source de-duplication backup software, here’s an example when used in conjunction with CBT enabled on a VM:
40GB VM without CBT = 1 hour and 20 minutes
100GB VM with CBT enabled = 2 minutes, 35 seconds
the ondly gotcha in CBT is that it does lower the VM performance a bit..
what mechanism is used to determine changed block by a VADP based software when CBT is not used ?
I will also try to get answers on the vmware forums.
Thanks.
Yeah I guess you’re right now that I think about it some more. I originally was thinking that the blocks were tracked at the VMFS volume level. Btw, here’s some more info I received from Anton Gostev from Veeam on CBT:
In essence, CBT is all about CTK files, these are the files which contain change tracking information of the corresponding VMDK file.
The concept is pretty simple, and if you are familiar with AD DirSync control, or Exchange ICS (public folders change tracking) – it is essentially the same: global USN (Update Sequence Number) for each object. CTK file describes the state of each block for tracking purposes, and contain USN for each block in the corresponding VMDK. After any block is updated, it is assigned the new global USN (which is previous USN value that was used on previously processed block plus 1). This way, any application can ask VMware API “tell me if this block was changed since THIS moment”, and the API will easily tell that by simply comparing the provided sequence number with the actual USN on each block. If provided USN is smaller than actual for particular block, it means that the block was changed (and needs to be backed up, replicated or otherwise processed). So multiple processes cannot conflict with each other anyhow. Each process just memorizes the USN corresponding to the snapshot that the application created during processing, and next time it will use the memorized USN to query for changed blocks.
There should be one CTK file per VMDK file, and CTK file cannot grow out of proportion with number of blocks in VMDK (as it stores only 1 record per VMDK block). CTK file is also thousands time smaller than actual VMDK, because it stores only a few bytes of information (USN) for each corresponding 256KB VMDK block (I am 90% sure it is 256KB, used to calculate it once using CTK debug/stats data, just don’t remember for sure – unimportant info escapes my head automatically to prevent overload with useless facts ;). For the same reasons, I/O overhead is barely noticeable with CBT: change few extra bytes to write for each 256000 bytes of data.
The CTK files are permanent, and should not be deleted after backup/replication.
I am investigating the CBT details for a major implementation (3k VMs) at a customer’s site and would like to have insights on what’s the block size.
Eric is implying it should be 256KB, can anybody confirm?
so how does we generate specific changed blocks for testing purpose? what I tried filling up 1GB VMDK with thousands of 64KB, then wipe out disk and refilled with 256KB files, however, cbt reports just < 20 blocks changed.