I’ve been playing around with Site Recovery Manager these last couple of days. Installing it was really easy and same goes for the basic configuration. I already wrote a blog about this topic a month ago or so but now I’ve experienced it myself. Most of the time during a Site Recover Manager project will be spent during the Plan & Design phase and writing documentation. I will just give you one example why. The following was taken from the SRM Course material:
Datastore Group
Replicated datastores containing the complete set of virtual machines that you want to protect with SRM
Protection Group
A group of virtual machines that are failed over together during test and recovery
For those who don’t know, there’s a one on one mapping between Datastore Groups and Protection Groups. So in other words, once you’ve mapped a Datastore Group to a Protection Group there’s no way of changing it without having to recreate the Protection Group.
I think a picture says more than a 1000 words so I stole this one from the Evaluator Guide to clarify the relationship between datastore, Datastore Groups and Protection Groups:
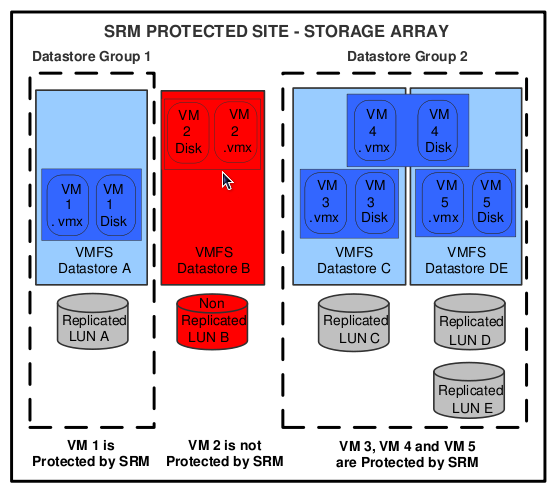
Notice that there are multiple datastores in Datastore Group 2 because VM4 has disks in both datastores. So these datastores are joined into one Datastore Group. This Datastore Group will have a one to one relationship with a Protection Group. Keep in mind, this is really important: a Protection Group contains VM’s that are failed over together during test and recovery.
If you’ve got VM’s with multiple disks on multiple datastores with no logic in which disk is placed on which datastore you could and probably will end up with all datastores being member of the same Datastore Group. Being member of the same Datastore Group means being part of the same Protection Group. Being part of the same Protection Group will result in a less granular fail-over. It’s all or nothing in this case and I can imagine most companies would like to have some sort of tiering model in place or even better fail over services one at a time. (This doesn’t mean by the way that if you create multiple Protection Group that you can’t fail over everything at the same time, they can all be joined in a Recovery Plan)
Some might think that you would be able to randomly add disks to datastores after you finished configuring. This clearly isn’t the case. If you add a disk to a protected(!) VM the Datastore Group will be recomputed. In our situation this meant that all VM’s in the “Medium Priority” Protection Group were moved over to the “High Priority” Protection Group. This was caused by the fact that we added a disk to a “Medium Priority” VM and placed it on a “High Priority” datastore. As you can imagine this also causes your Recovery Plans to end up with a “warning”, you will need to reconfigure the moved VM’s before you can fail them over as part of your “High Priority” datastore. (Which probably wasn’t the desired strategy…)
When I was searching the internet for information on SRM I stumbled upon this article on the VMware Uptime blog by Lee Dilworth. I’ve taken the following from the “What we’ve learnt” post, which confirms what we’ve seen the last couple of days:
Datastore Group computation is triggered by the following events:
- Existing VM is deleted or unregistered
- VM is storage vmotioned to a different datastore
- New disk is attached to VM on a datastore previously not used by the VM
- New datastore is created
- Existing datastore is expanded
So in other words, moving VM’s from one Datastore to another or creating a new disk on a different Datastore can cause problems because the Datastore Group computation will be re-run. Not only do you need to take virtual disk placement in consideration when configuring SRM, you will also need to be really careful when moving virtual disks. Documentation, Design and Planning is key here.
I would suggest documenting current disk placement before you even start implementing SRM, and given the results you might need to move disks around before you start with SRM. Make sure to check your documentation and design before randomly adding virtual disks when SRM has been implemented. Documenting your current disk placement can be done easily with the script that Hugo created this week by the way, and I would suggest to regularly create reports and save them.
Expect some more SRM stuff coming up over the next couple of weeks.
Great stuff Duncan!
What i don’t realize is in reality how you’re not really a lot more smartly-liked than you might be now. You’re so intelligent. You recognize therefore significantly relating to this matter, produced me for my part consider it from numerous numerous angles. Its like men and women aren’t involved except it is one thing to accomplish with Girl gaga! Your own stuffs great. All the time deal with it up!